9: Iteration
BSTA 526: R Programming for Health Data Science
2026-03-05
3.1 The for() loop way - first show iteration explicitly
- The
for()loop is a fundamental concept in computer programming.- This is the first step in automating over a long list (or vector!) of things.
- The idea is:
- If we do something once with a function,
- we can do it multiple times on different elements in a vector with that function.
- When we run the same function on different elements of a dataset, it is known as iteration.
- If we do something once with a function,
“In computer science a for-loop or for loop is a control flow statement for specifying iteration. Specifically, a for loop functions by running a section of code repeatedly until a certain condition has been satisfied.”
- In our case, the condition is usually that
- we’ve reached the end of the vector or list that we are indexing over.
- In the help documentation,
?fordefinition is:for(var in seq) {expr}
- Below we iterate across the vector
1:10. - The curly brackets
{}- contain functions/code block that you want to apply to each value in the vector, or to each “step”.
- In this case, we’re just printing out the values.
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
[1] 6
[1] 7
[1] 8
[1] 9
[1] 10- Slightly more complicated
- Note that you don’t have to use the word
indexfor the index!
- Note that you don’t have to use the word
# for each index in 1 to 10, do the thing inside {}
for(i in 1:10) { # using i as the index
print(i^2)
}[1] 1
[1] 4
[1] 9
[1] 16
[1] 25
[1] 36
[1] 49
[1] 64
[1] 81
[1] 100- We can do many things inside the brackets:
# for each index in 1 to 10, do the thing inside {}
for(numb in 1:10) { # using numb as the index
out <- numb - 1
print(numb)
print(out)
print(numb + out)
}[1] 1
[1] 0
[1] 1
[1] 2
[1] 1
[1] 3
[1] 3
[1] 2
[1] 5
[1] 4
[1] 3
[1] 7
[1] 5
[1] 4
[1] 9
[1] 6
[1] 5
[1] 11
[1] 7
[1] 6
[1] 13
[1] 8
[1] 7
[1] 15
[1] 9
[1] 8
[1] 17
[1] 10
[1] 9
[1] 19- The
indexis a placeholder. - It changes value each time we go through the loop (each iteration)
- It’s a way to refer to the element of the list that time around.
- It is not a variable that is meant to be used outside of the for loop.
- However, it is saved as an object (an aside: this is actually handy if your for loop exits on an error!):
- You also don’t need to use the index at all in your bracket code:
# for each index in 1 to 10, do the thing inside {}
for(index in 1:10) {
print(rnorm(n = 2)) # repeat the same thing 10 times
}[1] -0.5390307 -0.5743830
[1] -0.1927068 0.7310321
[1] -0.1725978 -1.5598219
[1] -1.2491829 0.8486965
[1] 2.4256132 0.2939203
[1] -0.74680967 -0.06463632
[1] -0.8560092 -0.8551662
[1] -0.2321517 0.6977850
[1] -1.315405 -1.118992
[1] 0.03040693 -1.26680178# for each index in the vector of pets, do the thing inside {}
pets <- c("dog", "cat", "mice")
for(index in pets) {
print(index)
}[1] "dog"
[1] "cat"
[1] "mice"- We can change the name of the index:
- A visual explanation (via Ted Laderas)


4 purrr: no need for for loops 🥳

4.2 purrr::map()
Enter the purrr package and map().
purrr::map()lets us apply a function to each element of a list.- It will always return a list with the number of elements that is the same as the list we input it with.
- Each slot of the returned list will contain the output of the functions applied to each element of the input list.
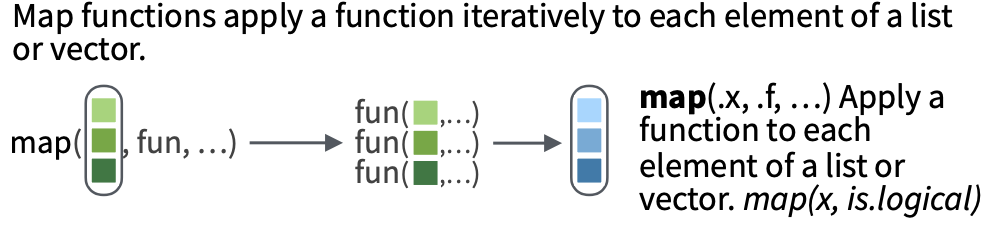
- The way to read a
map()statement is:
map(.x = LIST_OBJECT, .f = FUNCTION_TO_APPLY)
- Let’s make a function to return the first element of the input vector:
- We can apply this function to each element of a list, if the list contains vectors.
- This is usually easiest if the list is homogeneous,
- but this specific function can work for heterogeneous lists containing different kinds of vectors as well.
- The
forloop way is similar to theforloop where we printed the first element of the list on a previous slide:
# create my list
my_list <- list(cat_names = c("Morris", "Julia"),
hedgehog_names = "Spiny",
dog_names = c("Rover", "Spot", "Kitty"),
cat_ages = c(10,7))
# apply get_first_element to each element of my_list and save the output:
# create empty list
list_output <- list()
# for loop along the length of my list (in this case, 4)
for(index in 1:length(my_list)) {
# print out the index just so we can see what index is
print(index)
# in the index'th slot, put in the first element of this list
list_output[[index]] <- get_first_element(my_list[[index]])
}[1] 1
[1] 2
[1] 3
[1] 4[[1]]
[1] "Morris"
[[2]]
[1] "Spiny"
[[3]]
[1] "Rover"
[[4]]
[1] 10- That was….not simple.
- But
purrr::map()gives us a much simpler way!
- First let’s think about what the
forloop was doing,- with a more straightforward approach,
- but one that does not scale well:
# apply the function directly to each list element one by one
list_output_by_hand <-
list(
get_first_element(my_list[[1]]),
get_first_element(my_list[[2]]),
get_first_element(my_list[[3]]),
get_first_element(my_list[[4]])
)
list_output_by_hand[[1]]
[1] "Morris"
[[2]]
[1] "Spiny"
[[3]]
[1] "Rover"
[[4]]
[1] 10- Notice how we were applying the function to each element of the list,
- one at a time, until we ran out of list elements?
purrr::map()does this automatically, without writing out the function 4 (or many more) times.
- The function
map()usually takes two inputs:- the list to process
- the function to process the list items with
map(.x = LIST_OBJECT, .f = FUNCTION_TO_APPLY)
- Here’s the previous example using
map()instead of using aforloop.
$cat_names
[1] "Morris"
$hedgehog_names
[1] "Spiny"
$dog_names
[1] "Rover"
$cat_ages
[1] 10We have the same output as above using a
forloop,- but we even got to keep the original list names!
Note that we don’t call
get_first_element()with the parentheses - (similar to how we use functions by name inacross()and/orsummarize())We can also leave out the argument names for
map()if we like:
By default,
map()returns the results of your functions to a list.purrr::map()will work on lists or vectors or data frames.- We’re focusing on lists and vectors as input for now,
- because we have other ways of iterating across data frames (
summarize()andmutate(), for example), and - I don’t want to add too much confusion.