Day 12: Inference for a single proportion or difference of two (independent) proportions (Sections 8.1-8.2)
BSTA 511/611
2024-11-13
MoRitz’s tip of the day: code folding
- With code folding we can hide or show the code in the html output by clicking on the
Codebuttons in the html file. - Note the
</> Codebutton on the top right of the html output.

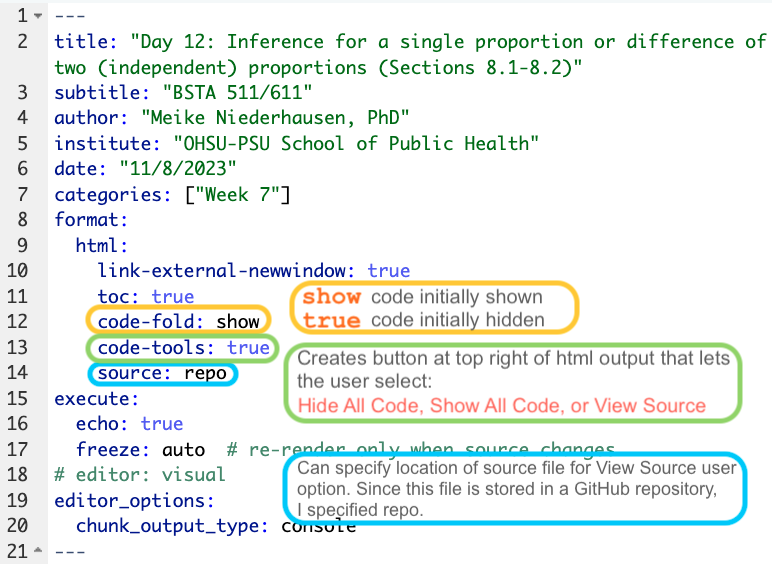

See more information at https://quarto.org/docs/output-formats/html-code.html#folding-code
Step 4: p-value
The p-value is the probability of obtaining a test statistic just as extreme or more extreme than the observed test statistic assuming the null hypothesis \(H_0\) is true.
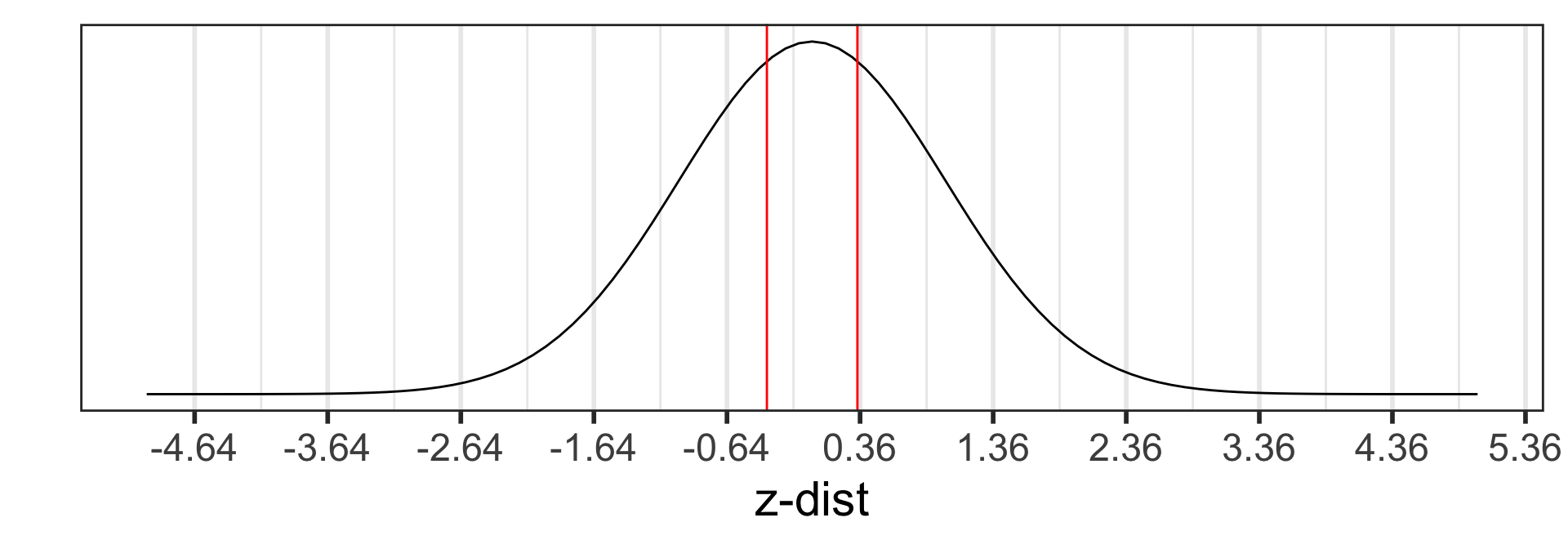
Step 4: p-value
The p-value is the probability of obtaining a test statistic just as extreme or more extreme than the observed test statistic assuming the null hypothesis \(H_0\) is true.
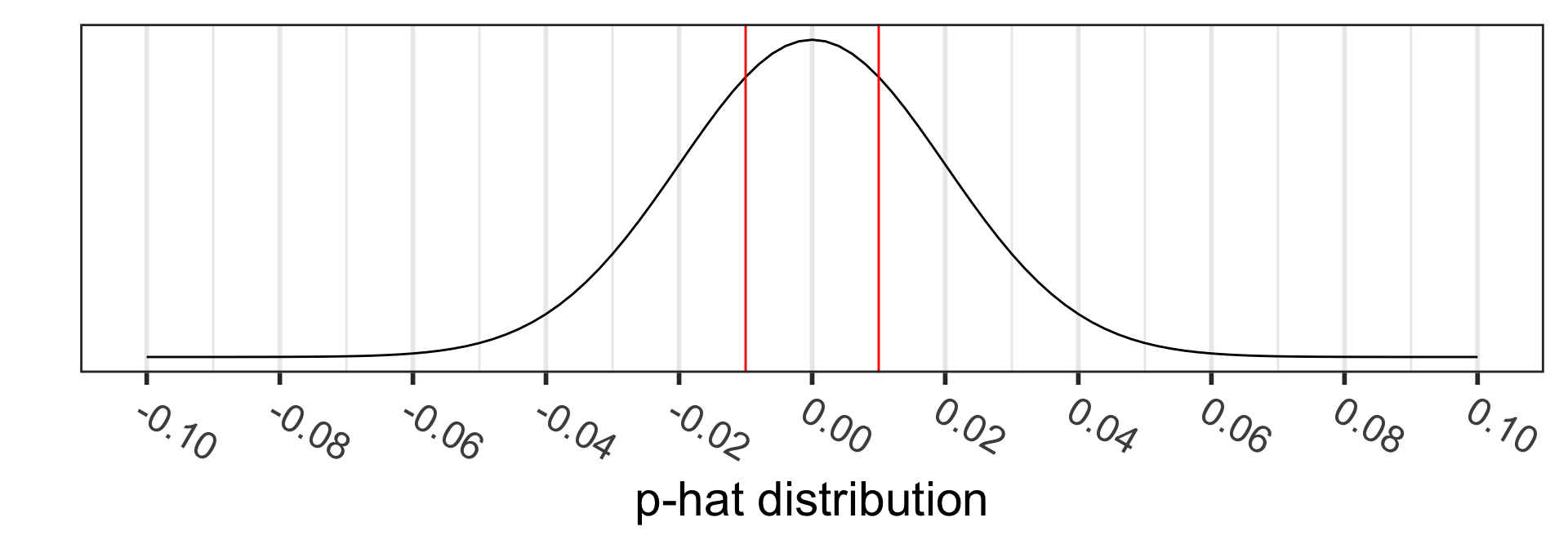
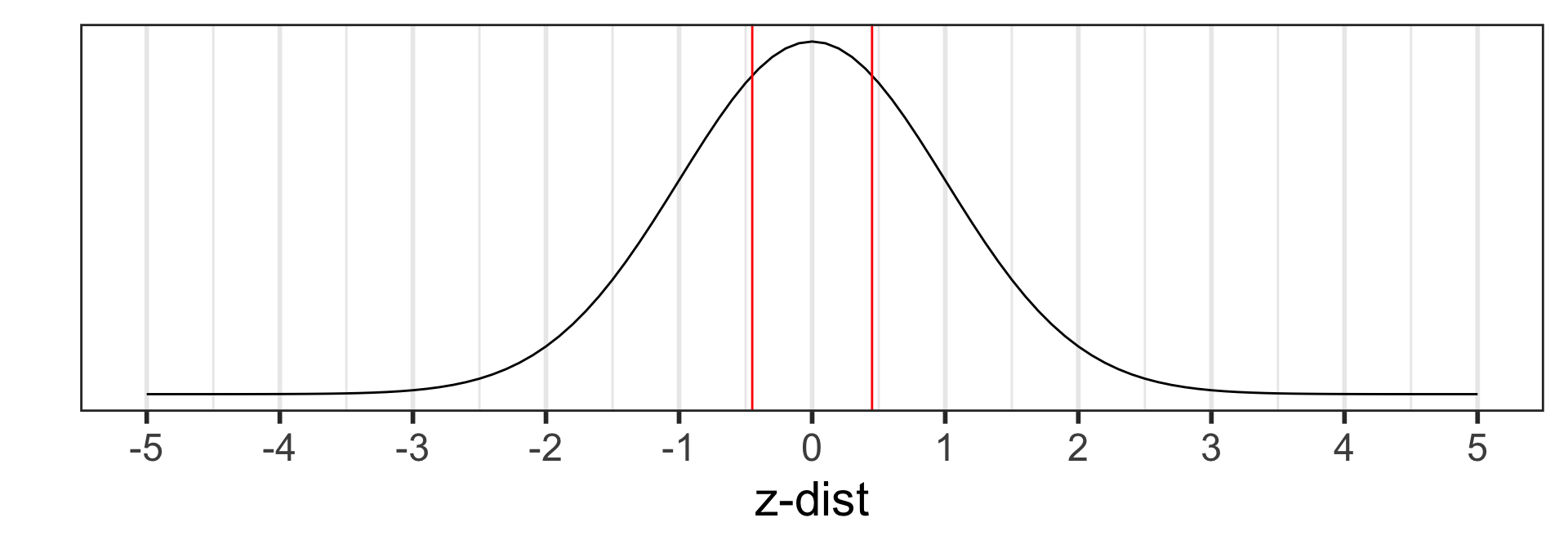
Calculate the p-value:
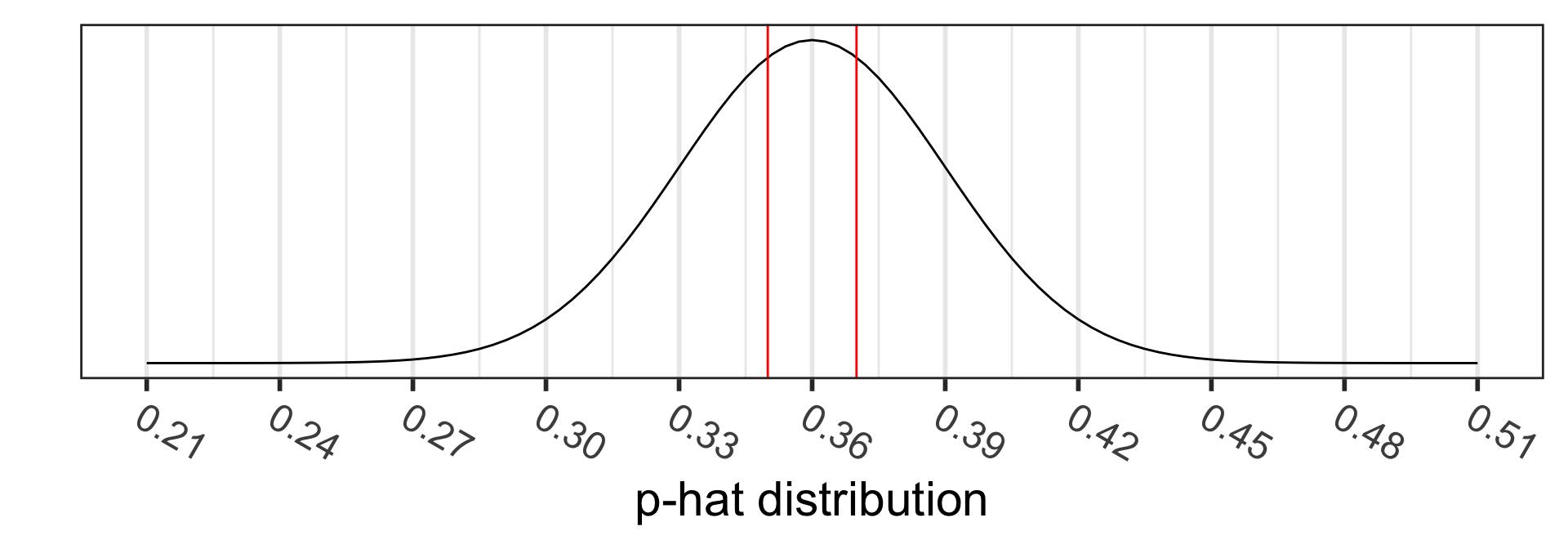
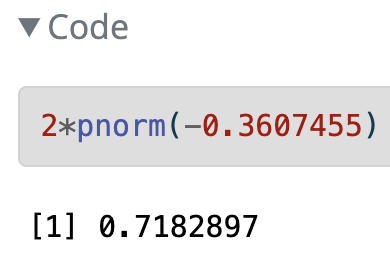
\[\begin{align} 2 &\cdot P(\hat{p}_1 - \hat{p}_2<0.35-0.36) \\ = 2 &\cdot P\Big(Z_{\hat{p}_1 - \hat{p}_2} < \\ &\frac{94/269 - 77/214-0}{\sqrt{0.354\cdot(1-0.354)(\frac{1}{269}+\frac{1}{214})}}\Big)\\ =2 &\cdot P(Z_{\hat{p}} < -0.2367497) \\ = & 0.812851 \end{align}\]
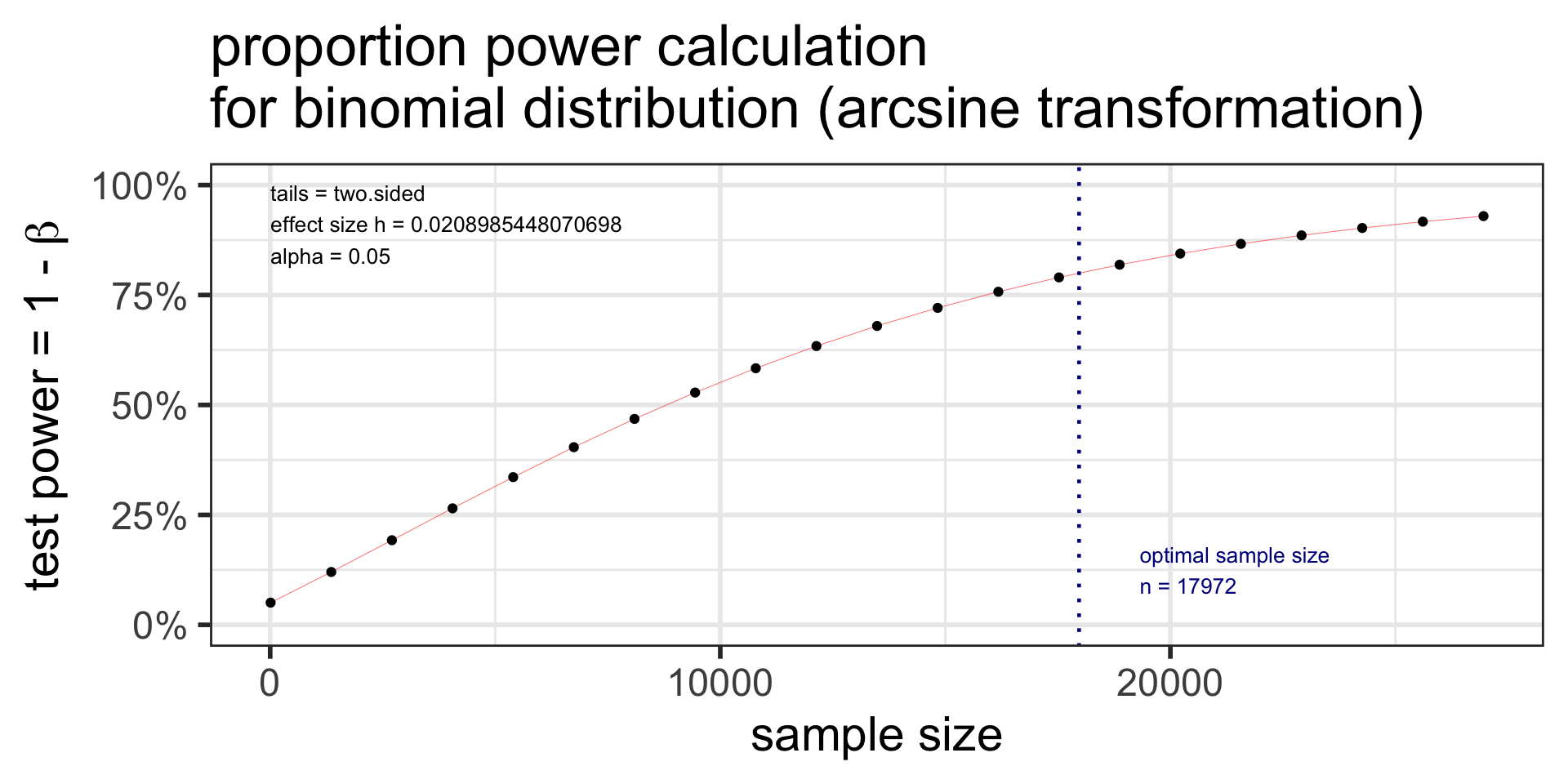
pwr: sample size for one proportion test
pwr.p.test(h = NULL, n = NULL, sig.level = 0.05, power = NULL, alternative = c("two.sided","less","greater"))
- \(h\) is the effect size:
h = ES.h(p1, p2)p1andp2are the two proportions being tested- one of them is the null proportion \(p_0\), and the other is the alternative proportion
Specify all parameters except for the sample size:
pwr: power for one proportion test
pwr.p.test(h = NULL, n = NULL, sig.level = 0.05, power = NULL, alternative = c("two.sided","less","greater"))
- \(h\) is the effect size:
h = ES.h(p1, p2)p1andp2are the two proportions being tested- one of them is the null proportion \(p_0\), and the other is the alternative proportion
Specify all parameters except for the power:
library(pwr)
p.power <- pwr.p.test(
h = ES.h(p1 = 0.36, p2 = 0.35),
sig.level = 0.05,
# power = 0.80,
n = 269,
alternative = "two.sided")
p.power
proportion power calculation for binomial distribution (arcsine transformation)
h = 0.02089854
n = 269
sig.level = 0.05
power = 0.06356445
alternative = two.sided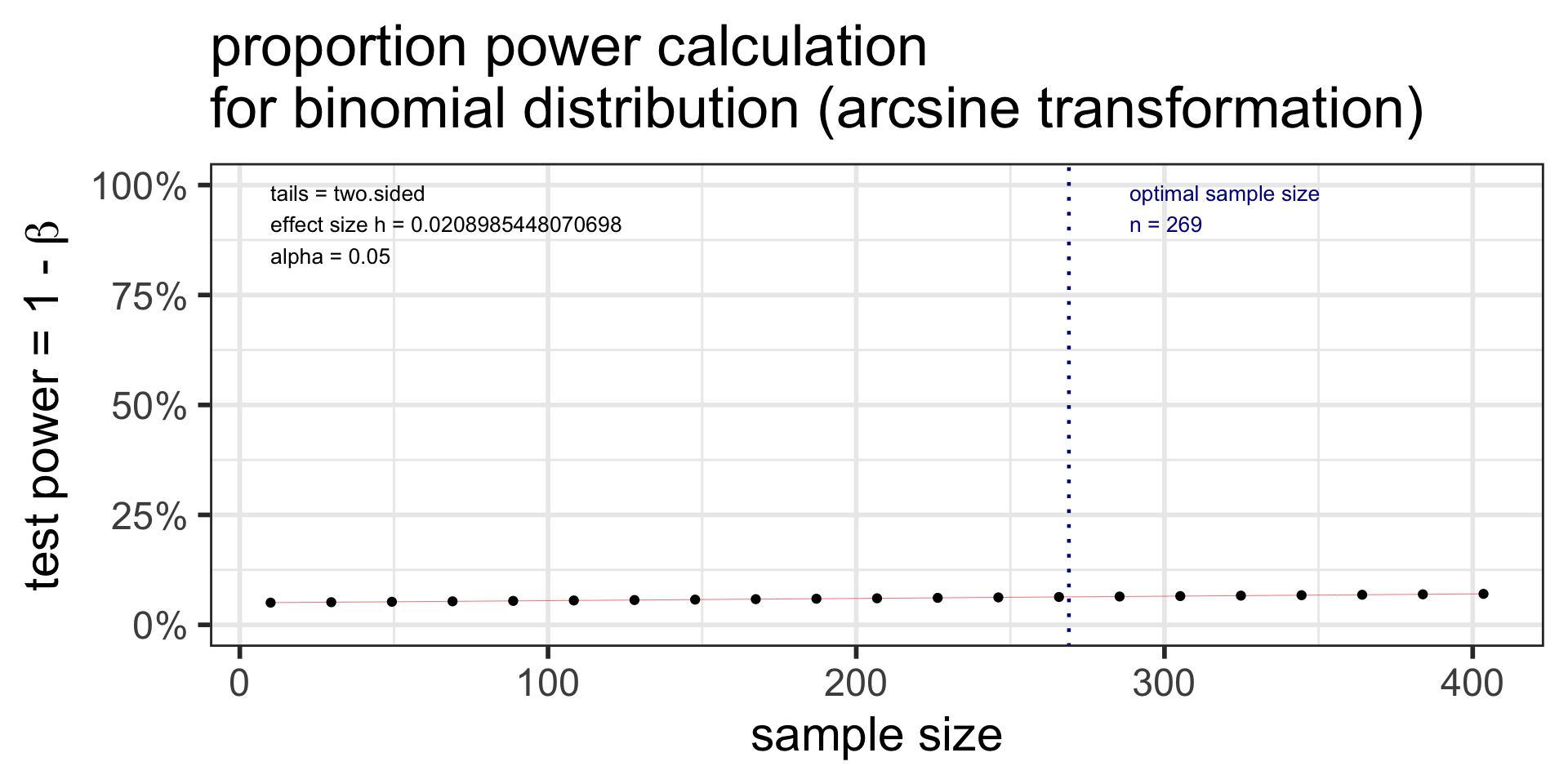
pwr: sample size for two proportions test
- Two proportions (same sample sizes)
pwr.2p.test(h = NULL, n = NULL, sig.level = 0.05, power = NULL, alternative = c("two.sided","less","greater"))
- \(h\) is the effect size:
h = ES.h(p1, p2);p1andp2are the two proportions being tested
Specify all parameters except for the sample size:
p2.n <- pwr.2p.test(
h = ES.h(p1 = 0.36, p2 = 0.35),
sig.level = 0.05,
power = 0.80,
alternative = "two.sided")
p2.n
Difference of proportion power calculation for binomial distribution (arcsine transformation)
h = 0.02089854
n = 35942.19
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: same sample sizes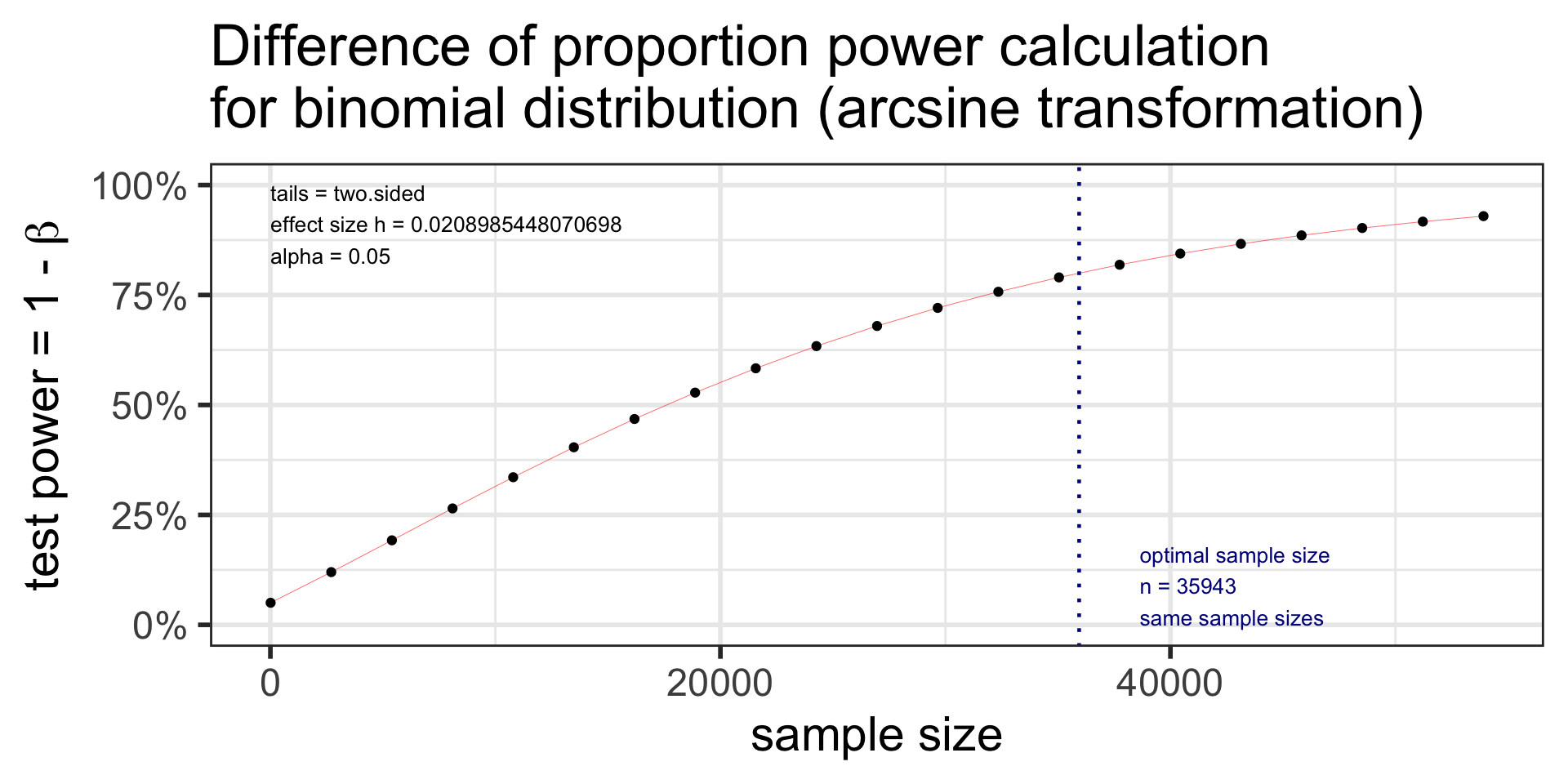
pwr: power for two proportions test
- Two proportions (different sample sizes)
pwr.2p2n.test(h = NULL, n1 = NULL, n2 = NULL, sig.level = 0.05, power = NULL, alternative = c("two.sided", "less","greater"))
- \(h\) is the effect size:
h = ES.h(p1, p2);p1andp2are the two proportions being tested
Specify all parameters except for the power:
p2.n2 <- pwr.2p2n.test(
h = ES.h(p1 = 0.36, p2 = 0.35),
n1 = 214,
n2 = 269,
sig.level = 0.05,
# power = 0.80,
alternative = "two.sided")
p2.n2
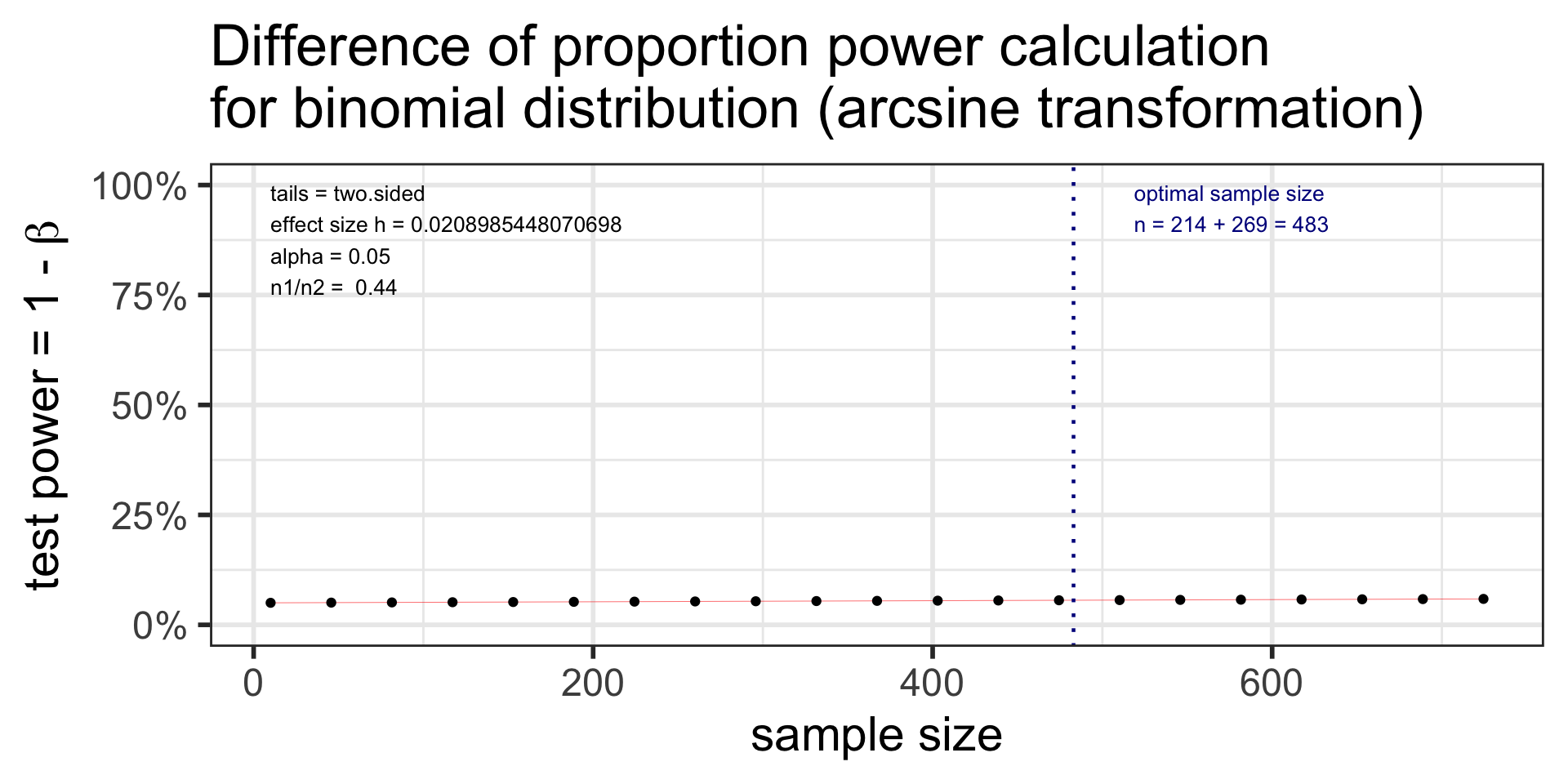
difference of proportion power calculation for binomial distribution (arcsine transformation)
h = 0.02089854
n1 = 214
n2 = 269
sig.level = 0.05
power = 0.05598413
alternative = two.sided
NOTE: different sample sizes