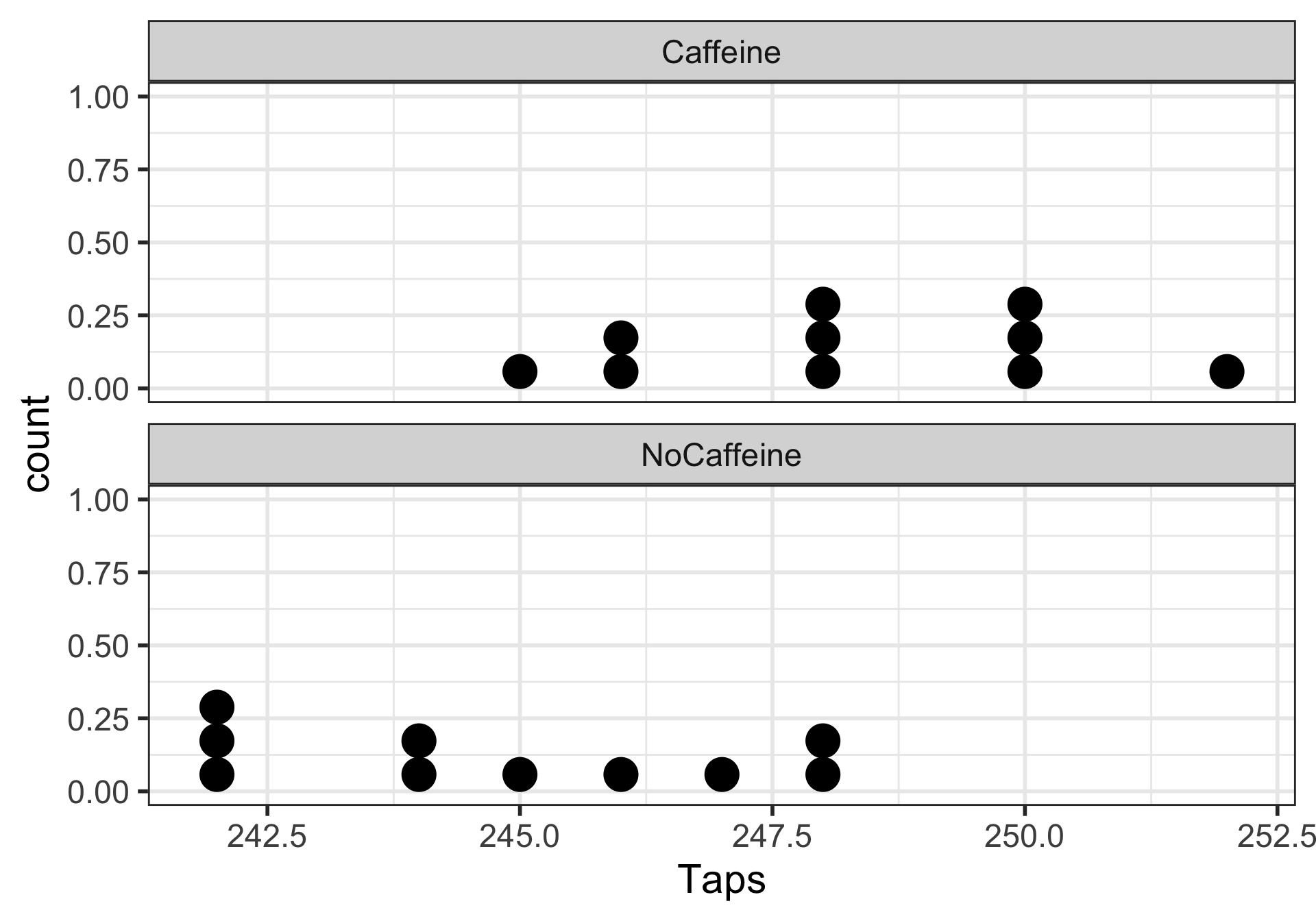
Rows: 20
Columns: 2
$ Taps <dbl> 246, 248, 250, 252, 248, 250, 246, 248, 245, 250, 242, 245, 244,…
$ Group <chr> "Caffeine", "Caffeine", "Caffeine", "Caffeine", "Caffeine", "Caf…Day 11: Inference for difference in means from two independent samples and Power (Sections 5.3, 5.4)
BSTA 511/611
2024-11-11
MoRitz’s tip of the day
Add tabbed sections to your html file using tabset.
- You can make subsections appear as different tabs in your html file.
- This is the first tab.
- It was created by adding
::: panel-tabsetright above the subsection### First tab(see the code file). - Look up to the right of where it says “First tab,” and you will see a second tab with the creative name “Second tab.”
- If you are viewing the html output of this file, you can click on the different tabs to see what’s in them.
- To stop new tabs from being created, close off the original
::: panel-tabsetcommand with:::at the end.- In the source code file, you will see the
:::at the end of the### Read up on tabsetstab.
- In the source code file, you will see the
- Welcome to the second tab!

- You can read up more about creating tabs at
If you are reading the source code file, the next line contains :::, which closes the tabsets.
Where are we?
Where are we? Continuous outcome zoomed in
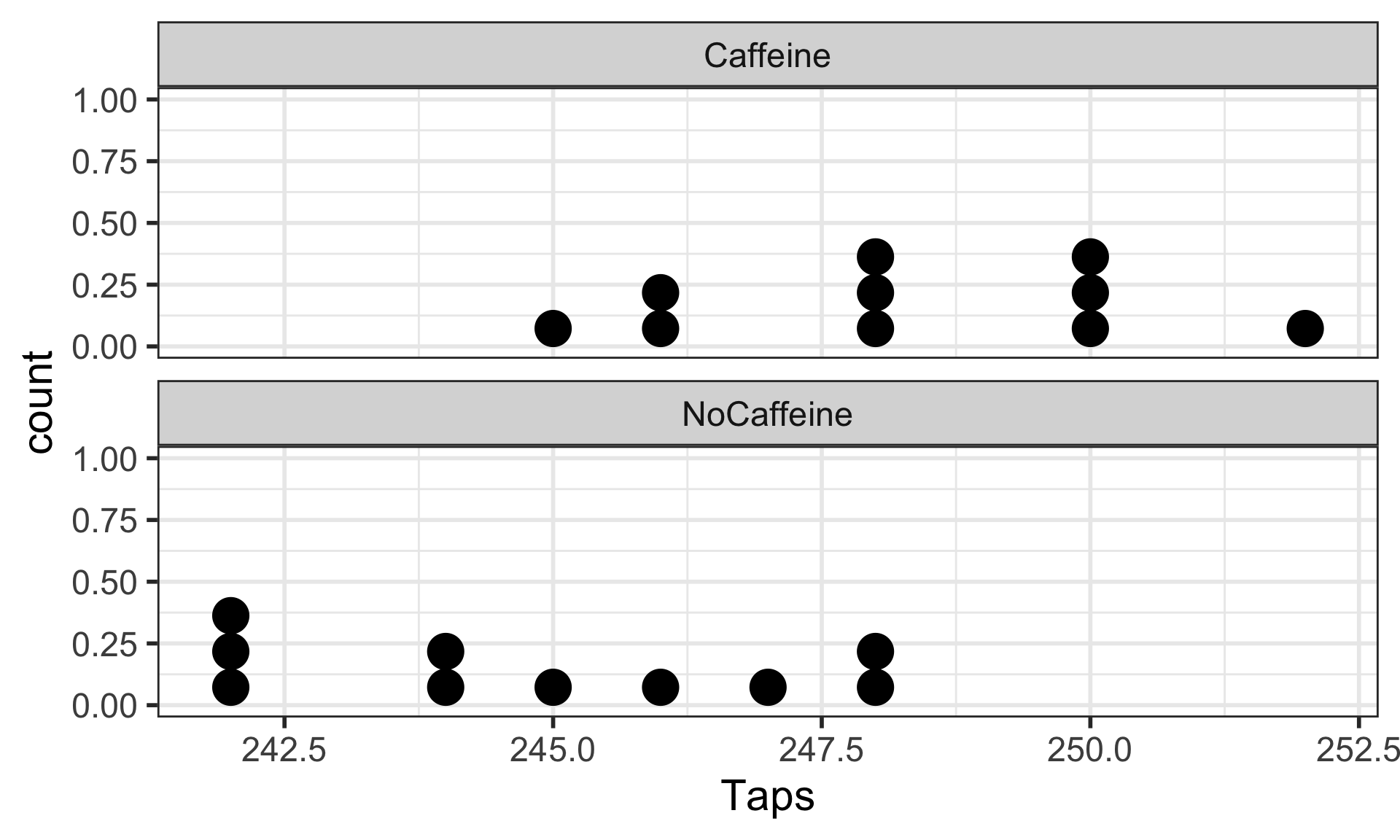
EDA: Explore the finger taps data
Dotplot of taps/minute stratified by group
Step “3b”: Assumptions satisfied?
Assumptions:
- Independent observations & samples
- The observations were collected independently.
- In particular, the observations from the two groups were not paired in any meaningful way.
- Approximately normal samples or big n’s
- The distributions of the samples should be approximately normal
- or both their sample sizes should be at least 30.
Step 4: p-value
The p-value is the probability of obtaining a test statistic just as extreme or more extreme than the observed test statistic assuming the null hypothesis \(H_0\) is true.
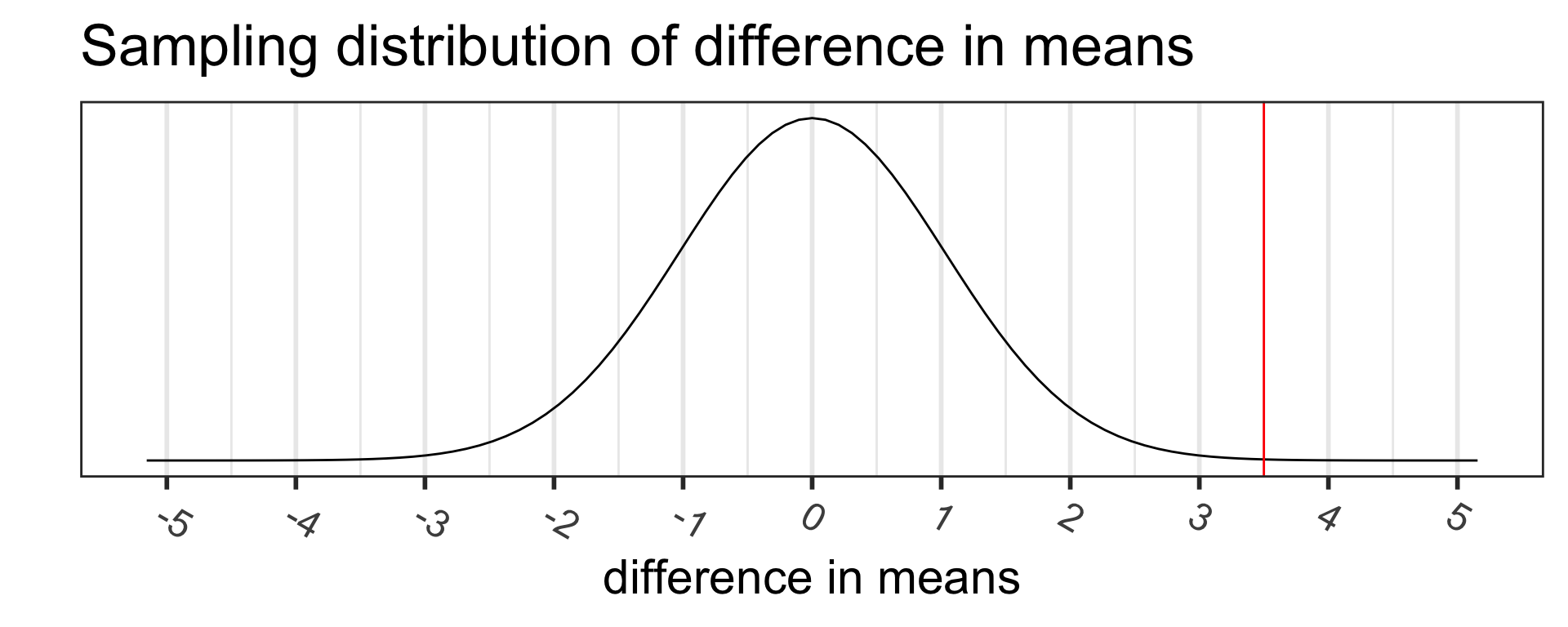
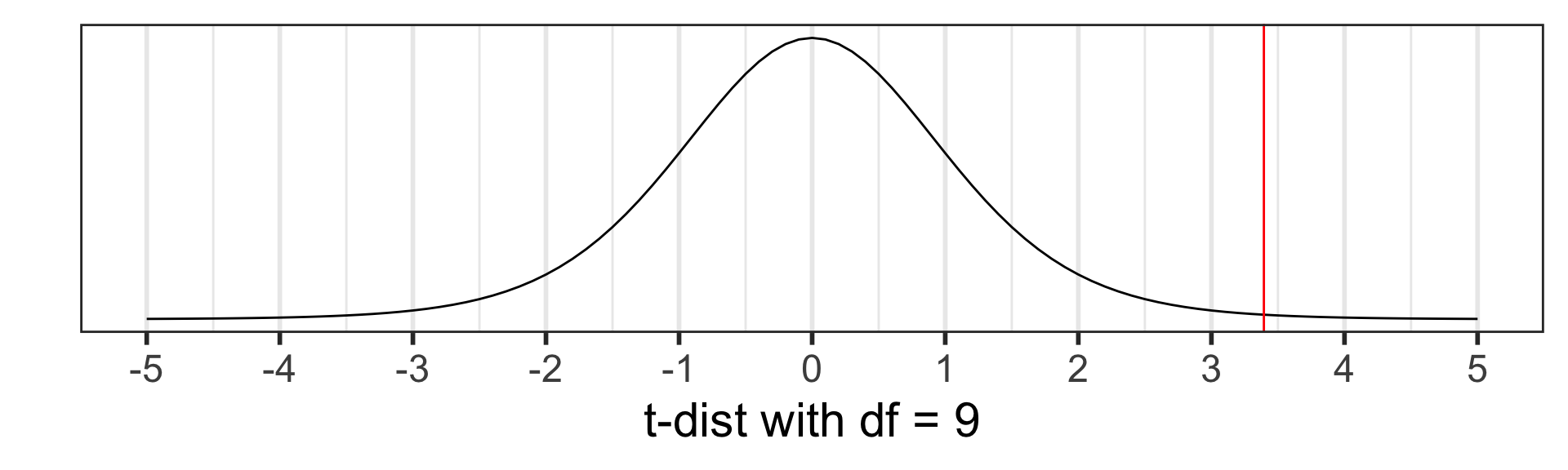
Calculate the p-value:
Critical values
- Critical values are the cutoff values that determine whether a test statistic is statistically significant or not.
- If a test statistic is greater in absolute value than the critical value, we reject \(H_0\)
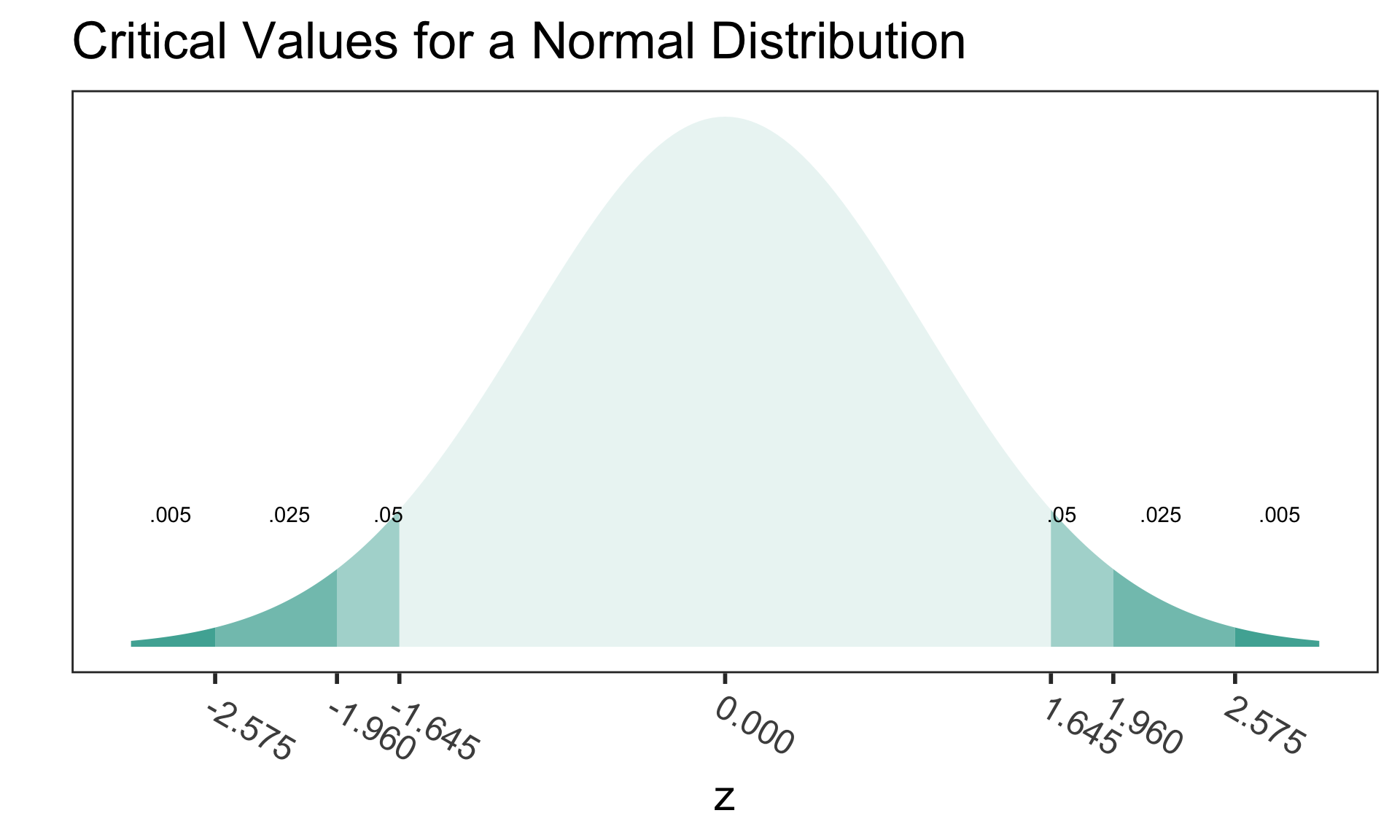
- Critical values are determined by
- the significance level \(\alpha\),
- whether a test is 1- or 2-sided, &
- the probability distribution being used to calculate the p-value (such as normal or t-distribution).
- The critical values in the figure should look very familiar!
- Where have we used these before?
- How can we calculate the critical values using R?
Rejection region
- If the absolute value of the test statistic is greater than the critical value, we reject \(H_0\)
- In this case the test statistic is in the rejection region.
- Otherwise it’s in the nonrejection region.
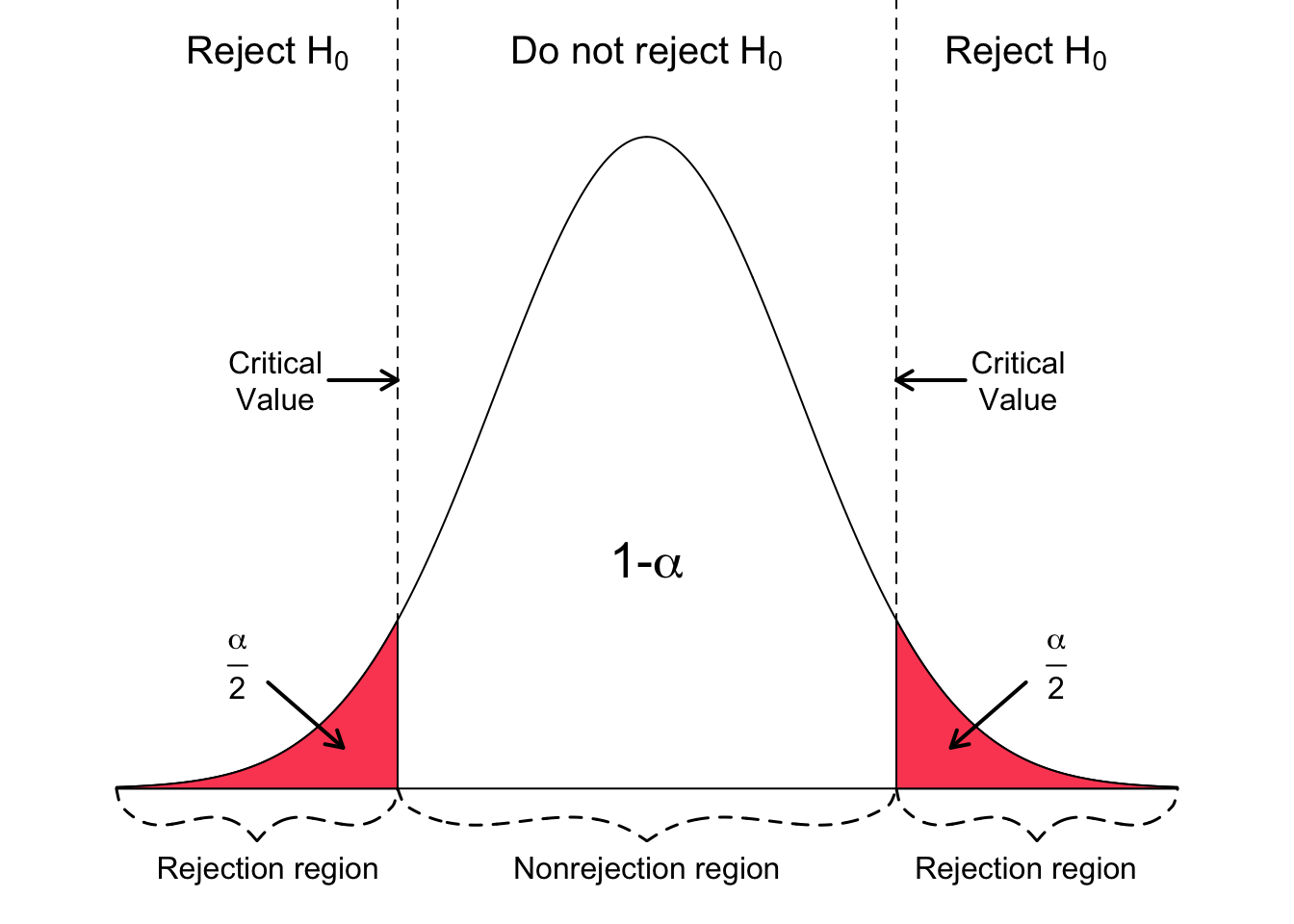
- What do rejection regions look like for 1-sided tests?
Hypothesis Testing “Errors”

Justice system analogy

Type I and Type II Errors - Making Mistakes in the Justice System
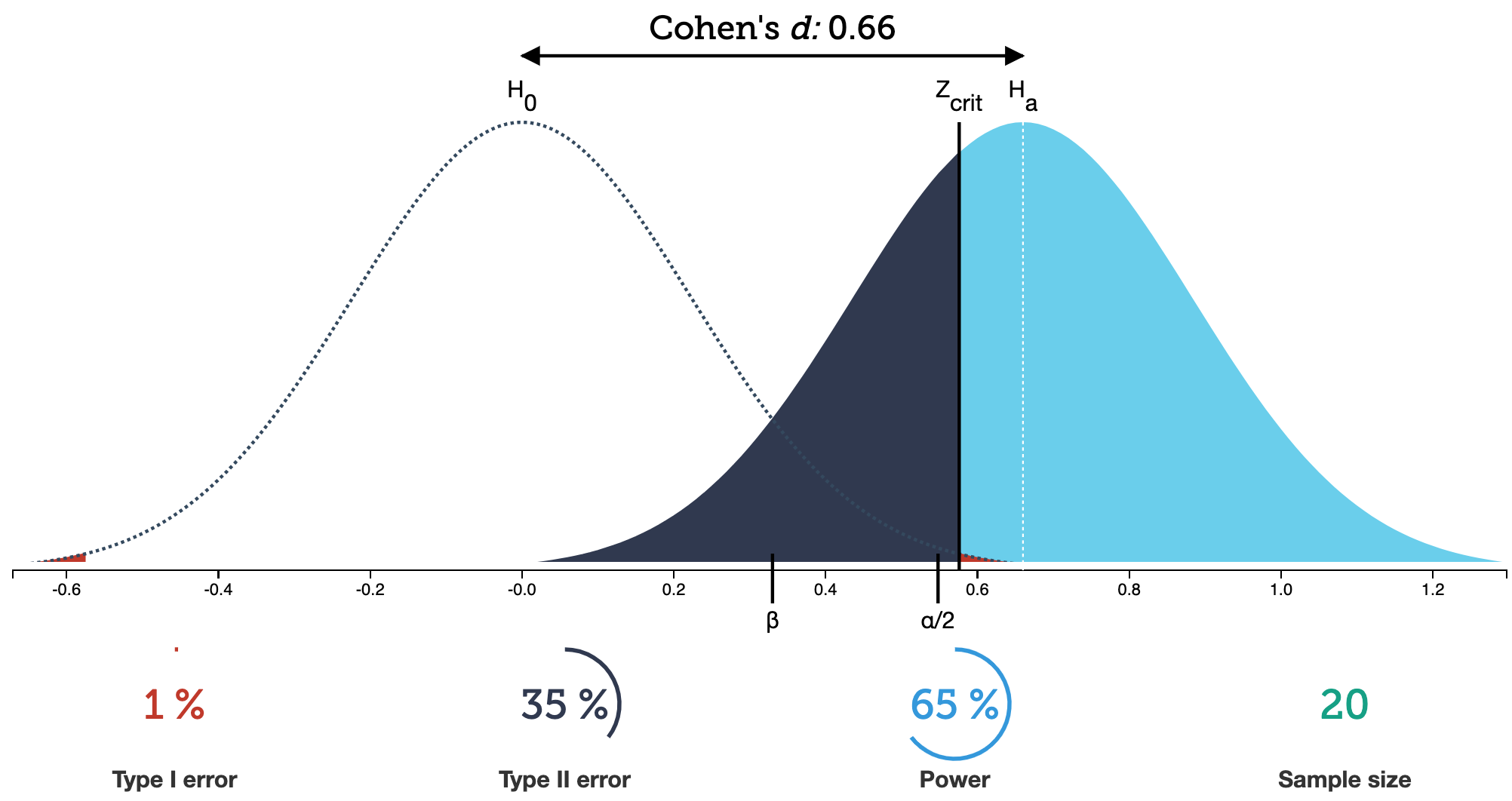
Type I & II Errors
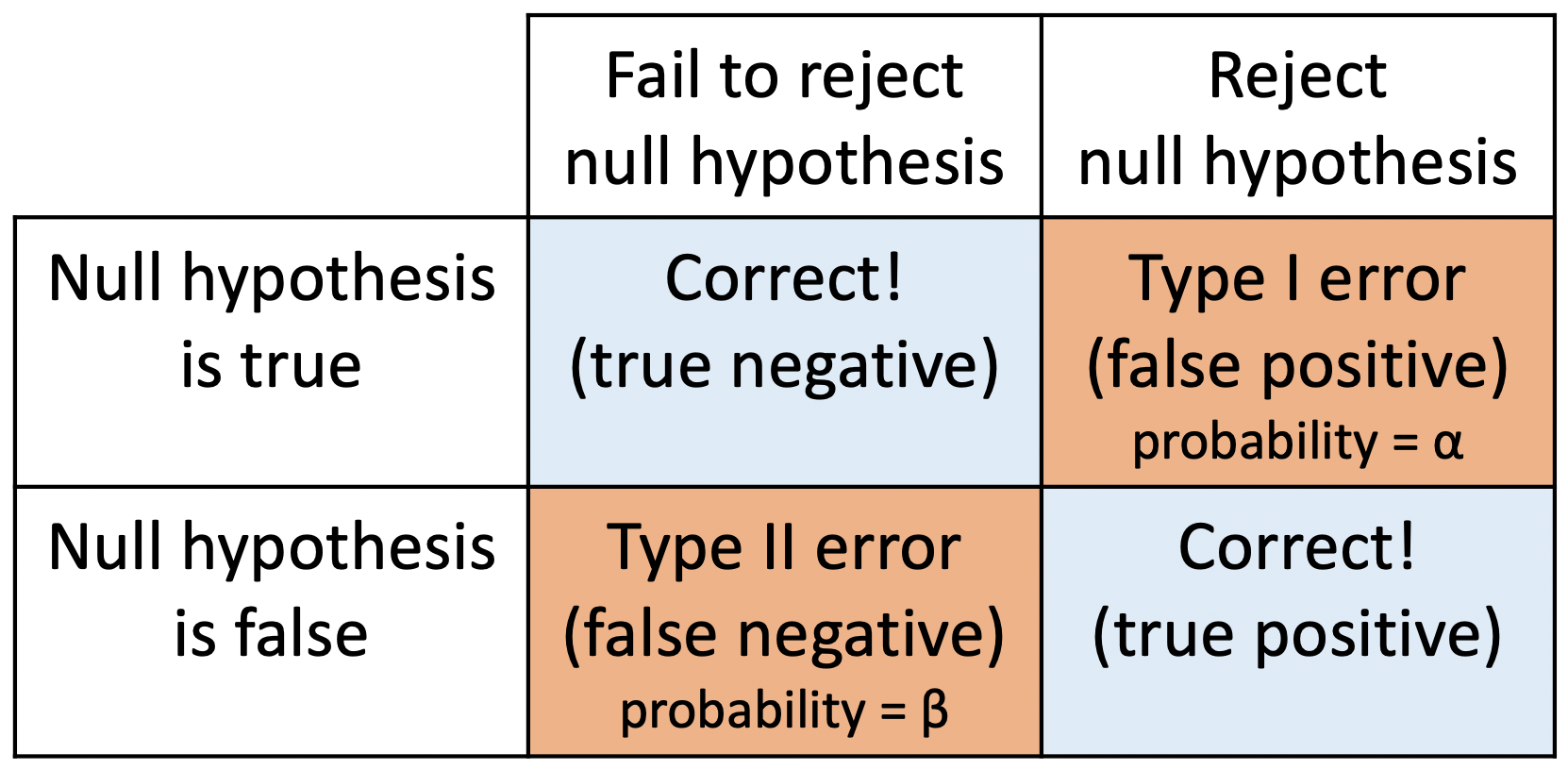
- \(\alpha\) = probability of making a Type I error
- This is the significance level (usually 0.05)
- Set before study starts
- \(\beta\) = probability of making a Type II error
- Ideally we want
- small Type I & II errors and
- big power
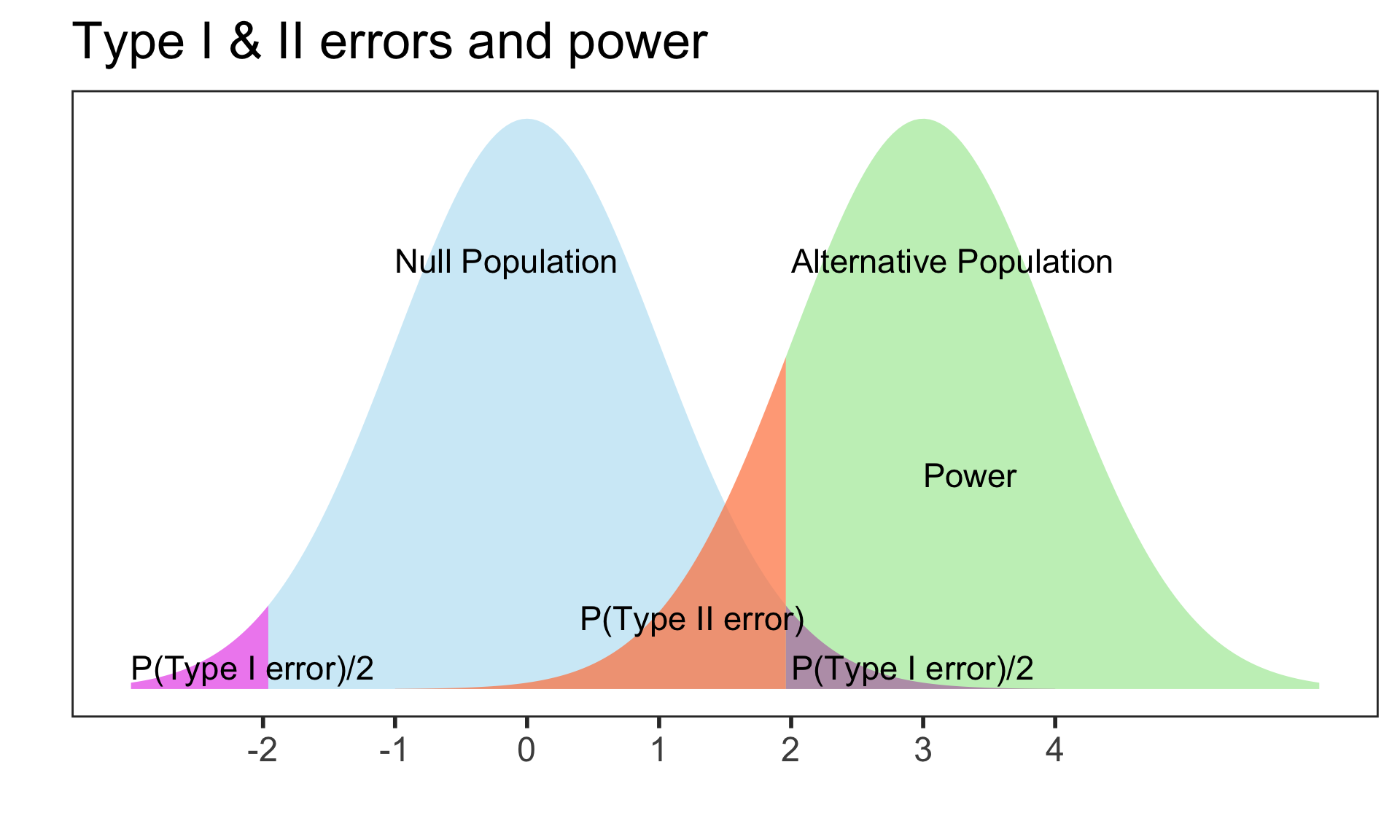
Applet for visualizing Type I & II errors and power: https://rpsychologist.com/d3/NHST/
Relationship between Type I & II errors
- Type I vs. Type II error
- Decreasing P(Type I error) leads to
- increasing P(Type II error)
- We typically keep P(Type I error) = \(\alpha\) set to 0.05
- Decreasing P(Type I error) leads to
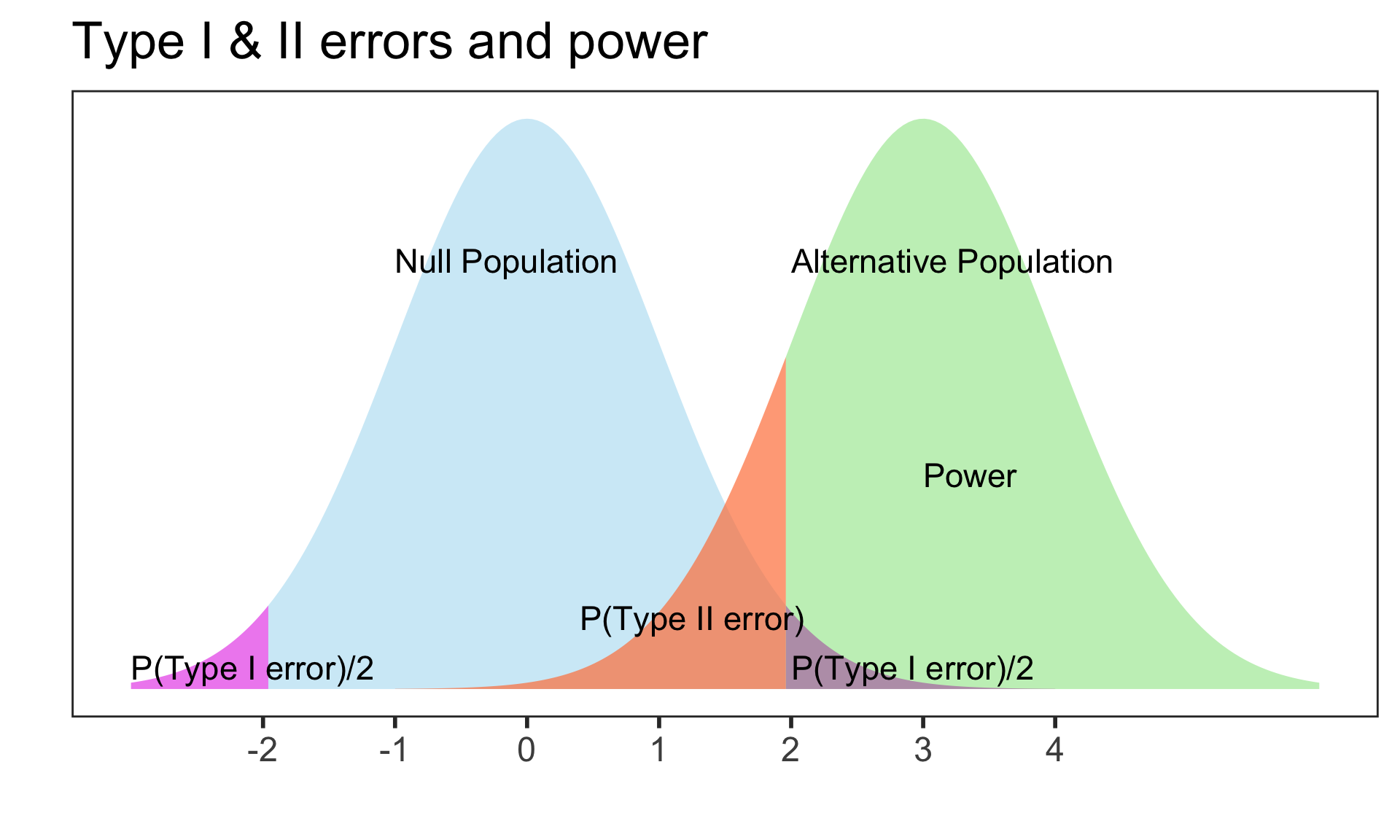
From the applet at https://rpsychologist.com/d3/NHST/
Relationship between Type II errors and power
- Power is also called the
- true positive rate,
- probability of detection, or
- the sensitivity of a test
Power vs. Type II error
Power = 1 - P(Type II error) = 1 - \(\beta\)
Thus as \(\beta\) = P(Type II error) decreases, the power increases
P(Type II error) decreases as the mean of the alternative population shifts further away from the mean of the null population (effect size gets bigger).
Typically want at least 80% power; 90% power is good
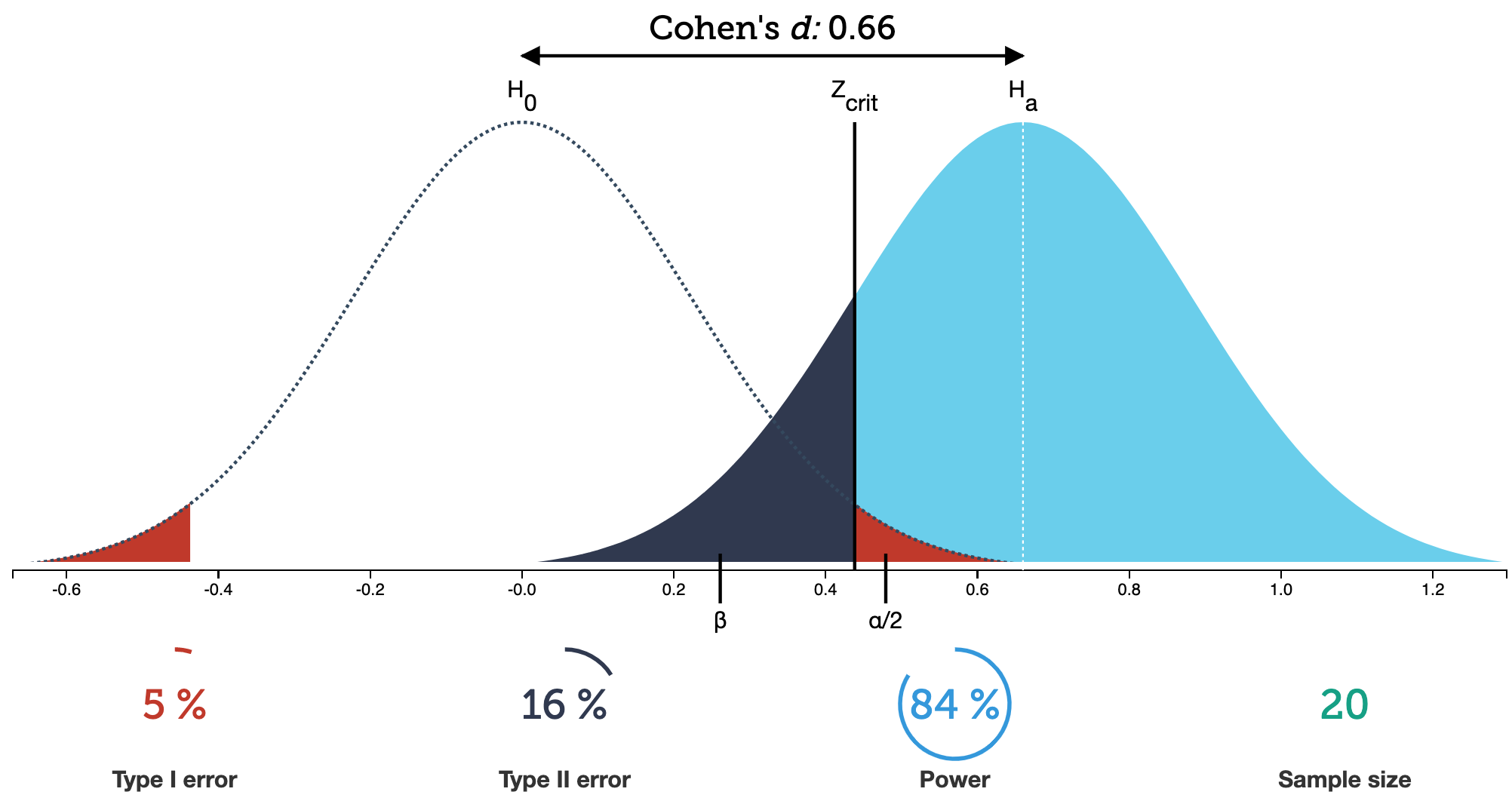
Example calculating power
- Suppose the mean of the null population is 0 ( \(H_0: \mu=0\) ) with standard error 1
- Find the power of a 2-sided test if the actual \(\mu=3\), assuming the SE doesn’t change.
- Power = \(P(\)Reject \(H_0\) when alternative pop is \(N(3,1))\)
- When \(\alpha\) = 0.05, we reject \(H_0\) when the test statistic z is at least 1.96
- Thus for \(X\sim N(3,1)\) we need to calculate \(P(X \le -1.96) + P(X \ge 1.96)\):
The left tail probability pnorm(-1.96, mean=3, sd=1, lower.tail=TRUE) is essentially 0 in this case.
- Note that this power calculation specified the value of the SE instead of the standard deviation and sample size \(n\) individually.
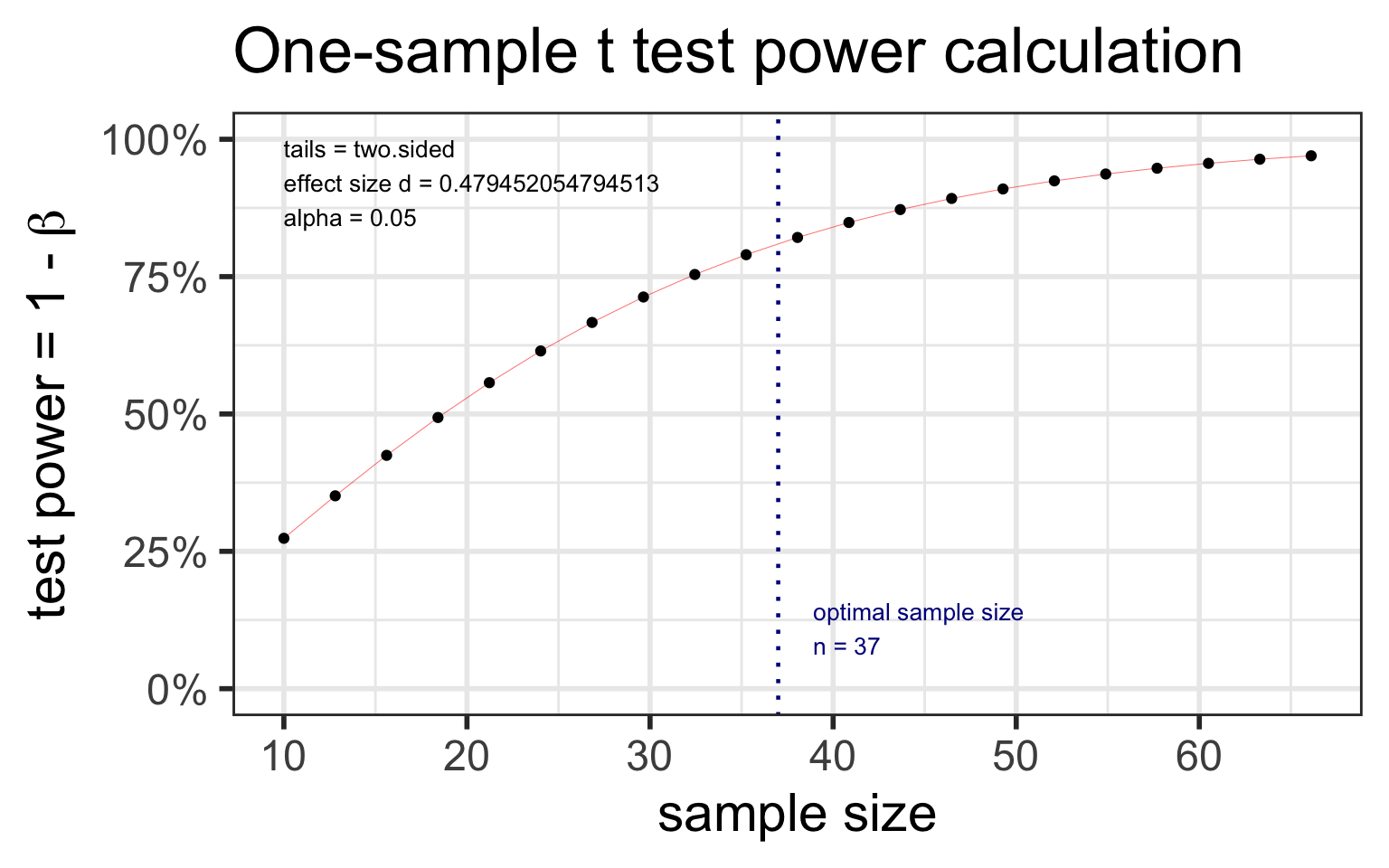
pwr: sample size for one mean test
pwr.t.test(n = NULL, d = NULL, sig.level = 0.05, power = NULL,
type = c("two.sample", "one.sample", "paired"), alternative = c("two.sided", "less", "greater"))
dis Cohen’s d effect size: \(d = \frac{\mu-\mu_0}{s}\)
Specify all parameters except for the sample size:
pwr: power for one mean test
pwr.t.test(n = NULL, d = NULL, sig.level = 0.05, power = NULL,
type = c("two.sample", "one.sample", "paired"), alternative = c("two.sided", "less", "greater"))
dis Cohen’s d effect size: \(d = \frac{\mu-\mu_0}{s}\)
Specify all parameters except for the power:
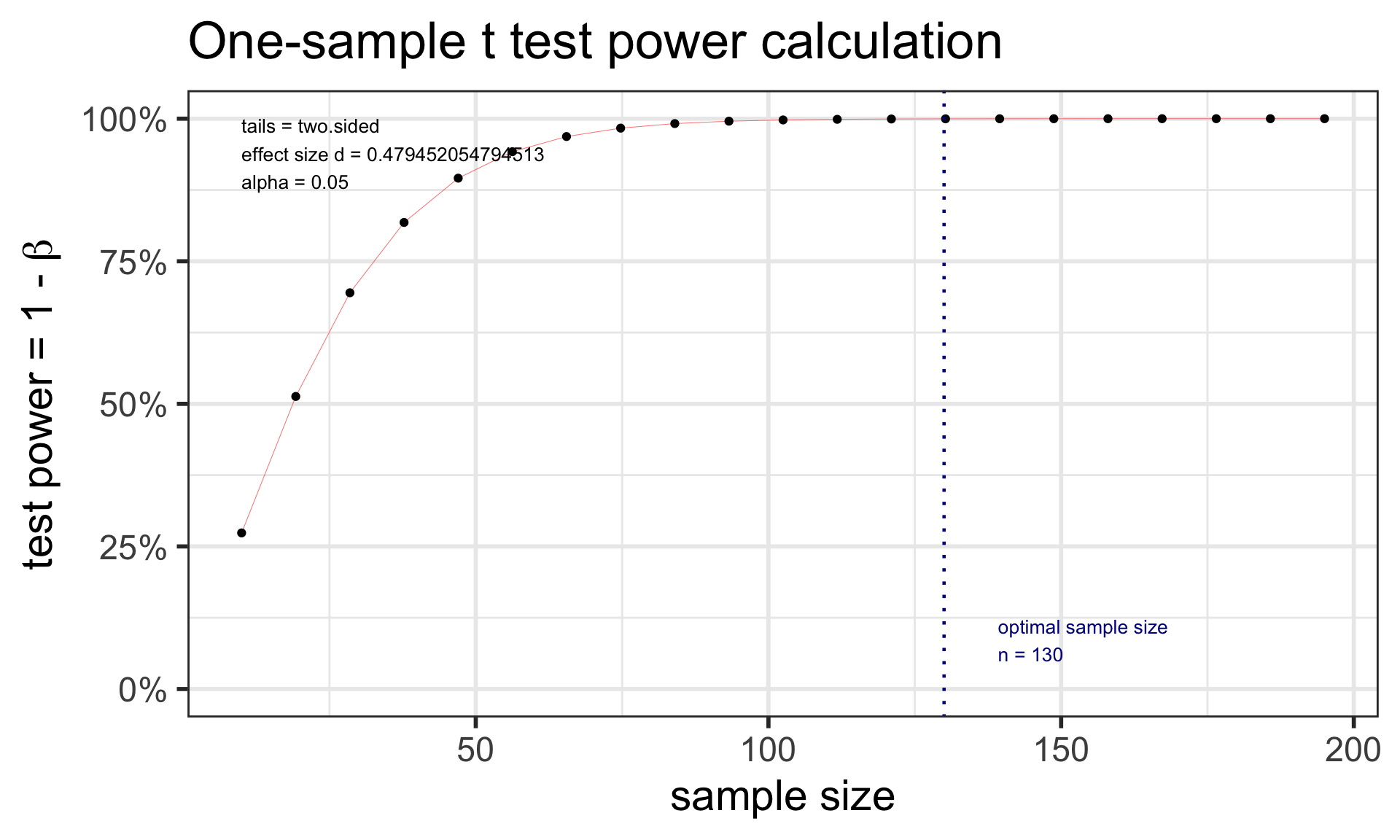
pwr: Two-sample t-test: sample size
pwr.t.test(n = NULL, d = NULL, sig.level = 0.05, power = NULL,
type = c("two.sample", "one.sample", "paired"), alternative = c("two.sided", "less", "greater"))
dis Cohen’s d effect size: \(d = \frac{\bar{x}_1 - \bar{x}_2}{s_{pooled}}\)
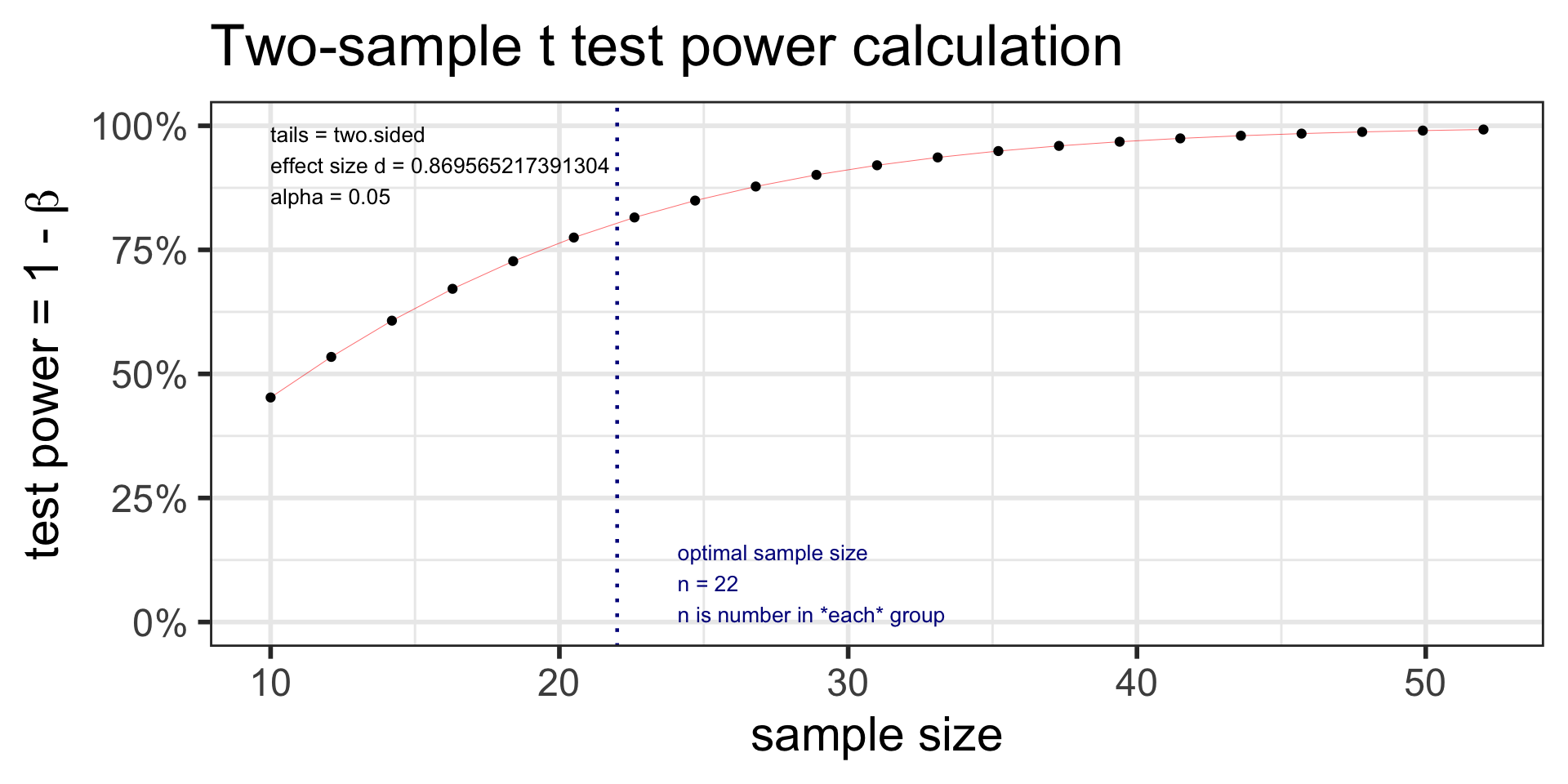
Example: Suppose the data collected for the caffeine taps study were pilot day for a larger study. Investigators want to know what sample size they would need to detect a 2 point difference between the two groups. Assume the SD in both groups is 2.3.
Specify all parameters except for the sample size:
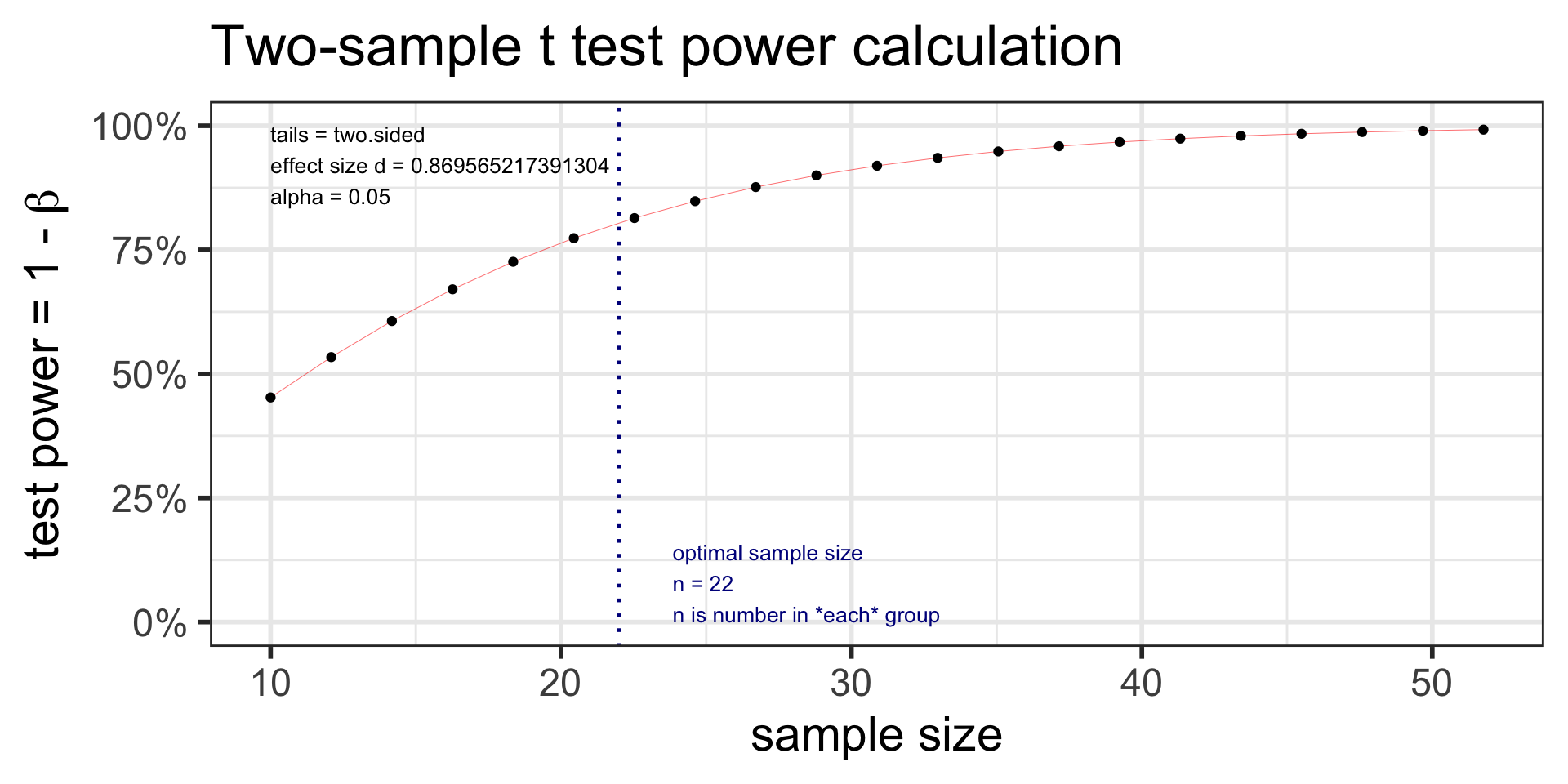
pwr: Two-sample t-test: power
pwr.t.test(n = NULL, d = NULL, sig.level = 0.05, power = NULL,
type = c("two.sample", "one.sample", "paired"), alternative = c("two.sided", "less", "greater"))
dis Cohen’s d effect size: \(d = \frac{\bar{x}_1 - \bar{x}_2}{s_{pooled}}\)
Example: Suppose the data collected for the caffeine taps study were pilot day for a larger study. Investigators want to know what sample size they would need to detect a 2 point difference between the two groups. Assume the SD in both groups is 2.3.
Specify all parameters except for the power: