Day 8: Variability in estimates
BSTA 511/611
2024-10-28
Where are we?
Goals for today
Section 4.1
- Sampling from a population
- population parameters vs. point estimates
- sampling variation
- Sampling distribution of the mean
- Central Limit Theorem

MoRitz’s tip of the day: add a code pane in RStudio
Do you want to be able to view two code files side-by-side?
You can do that by adding a column to the RStudio layout.
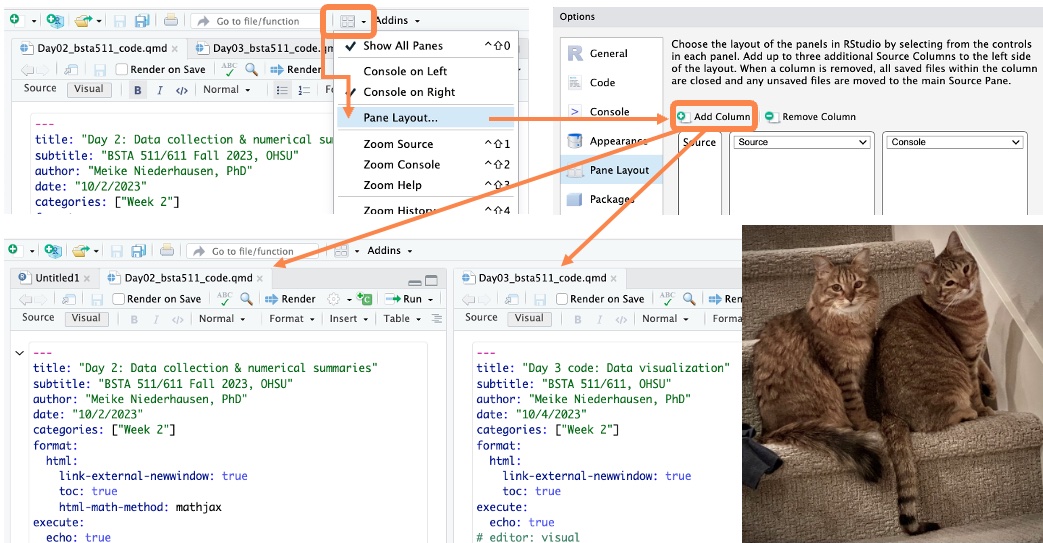
See https://posit.co/blog/rstudio-1-4-preview-multiple-source-columns/ for more information.
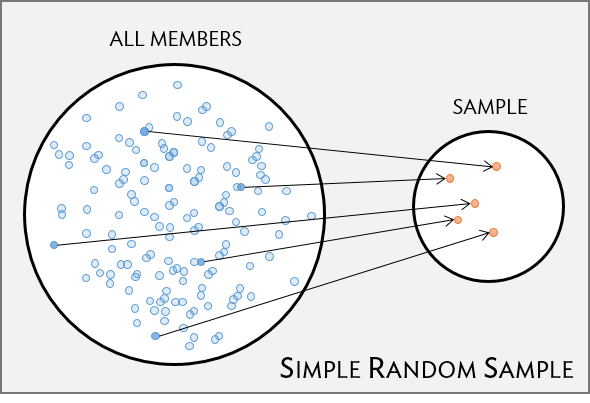
Population vs. sample (from section 1.3)
(Target) Population
- group of interest being studied
- group from which the sample is selected
- studies often have inclusion and/or exclusion criteria
Sample
- group on which data are collected
- often a small subset of the population
Simple random sample (SRS)
- each individual of a population has the same chance of being sampled
- randomly sampled
- considered best way to sample
Height & weight variables
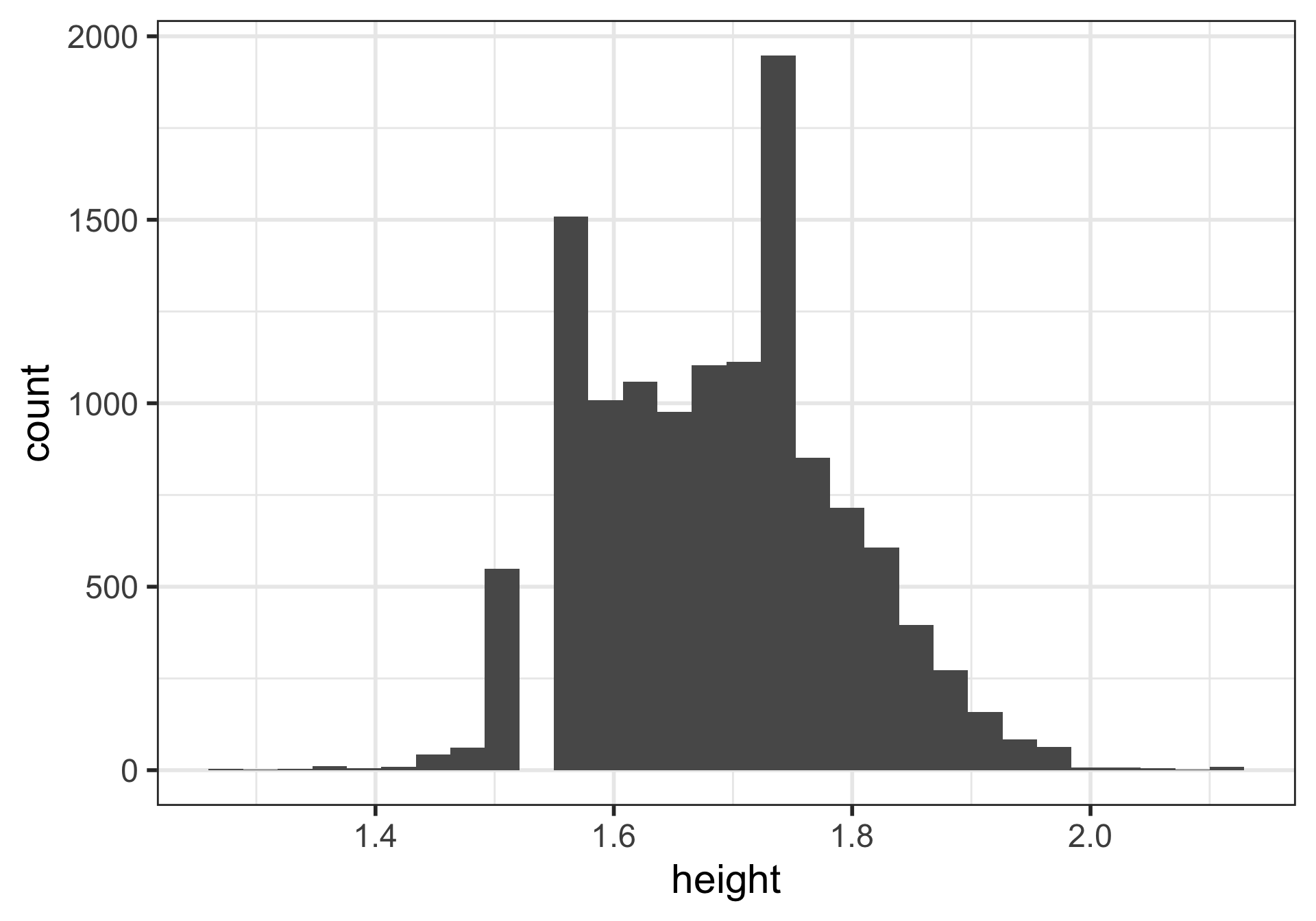
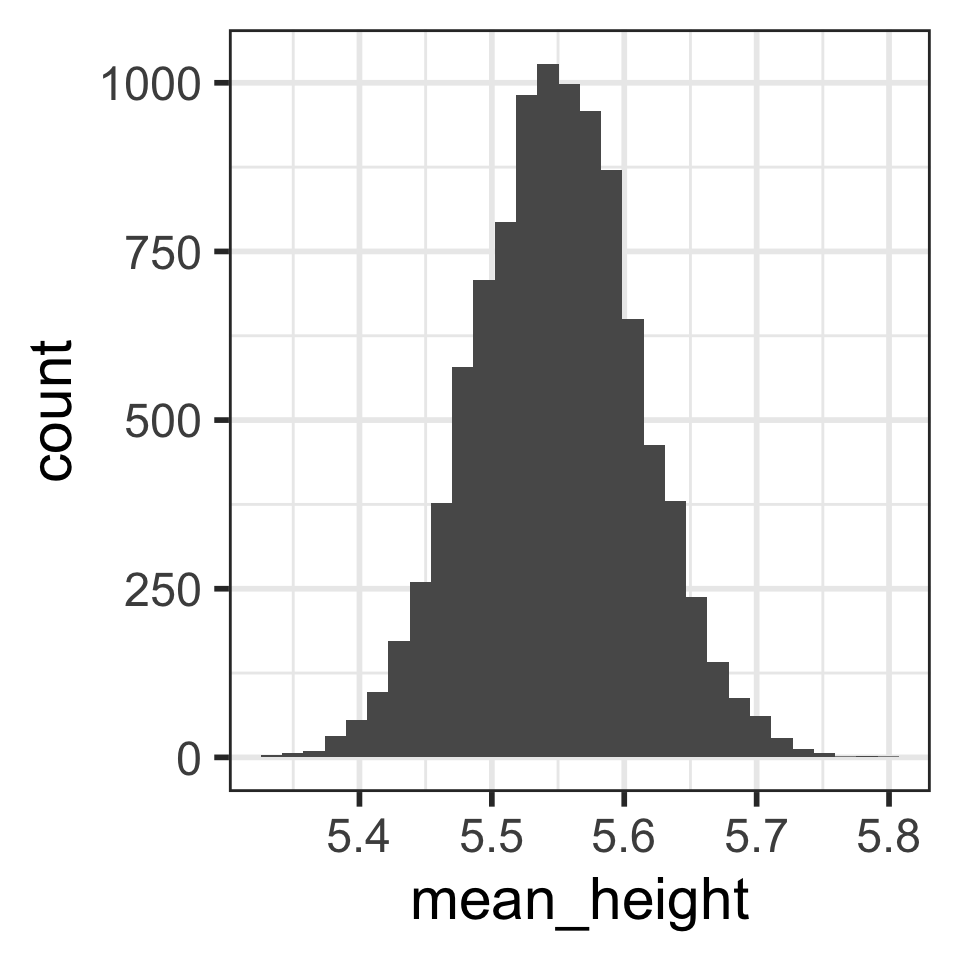
Distribution of 100 sample mean heights (n = 5)
Describe the distribution shape.
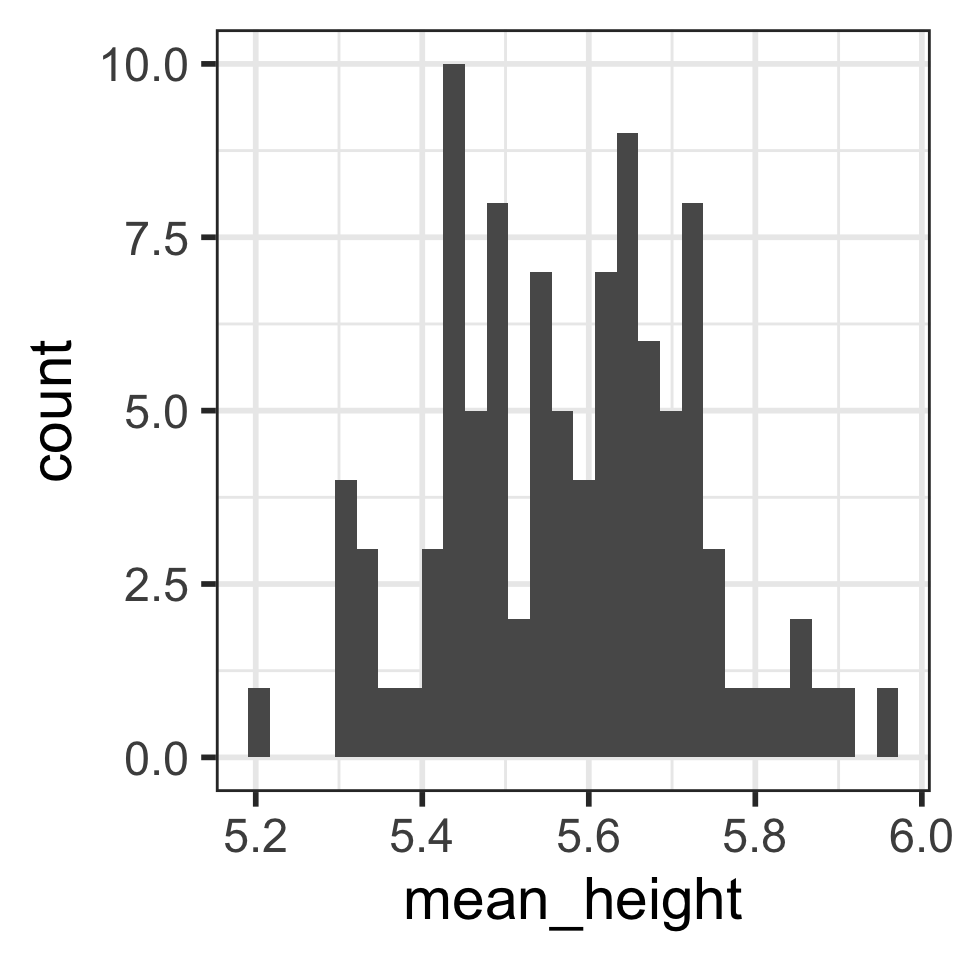
Calculate the mean and SD of the 100 mean heights from the 100 samples:
stats_means_hght_samp_n5_rep100 <-
means_hght_samp_n5_rep100 %>%
summarise(
mean_mean_height = mean(mean_height),
sd_mean_height = sd(mean_height)
)
stats_means_hght_samp_n5_rep100# A tibble: 1 × 2
mean_mean_height sd_mean_height
<dbl> <dbl>
1 5.58 0.150Is the mean of the means close to the “center” of the distribution?
Distribution of 10,000 sample mean heights (n = 5)
Describe the distribution shape.
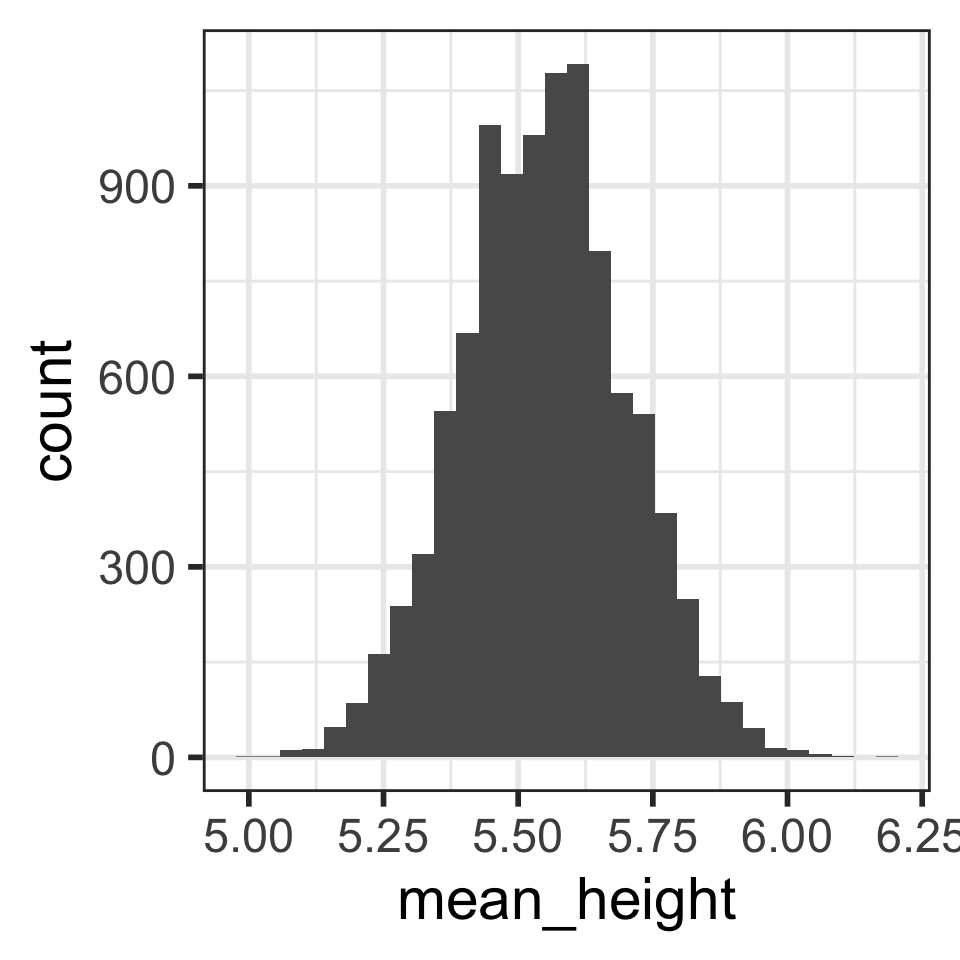
Calculate the mean and SD of the 10,000 mean heights from the 10,000 samples:
stats_means_hght_samp_n5_rep10000 <-
means_hght_samp_n5_rep10000 %>%
summarise(
mean_mean_height=mean(mean_height),
sd_mean_height = sd(mean_height)
)
stats_means_hght_samp_n5_rep10000# A tibble: 1 × 2
mean_mean_height sd_mean_height
<dbl> <dbl>
1 5.55 0.153Is the mean of the means close to the “center” of the distribution?
Distribution of 10,000 sample mean heights (n = 30)
Describe the distribution shape.
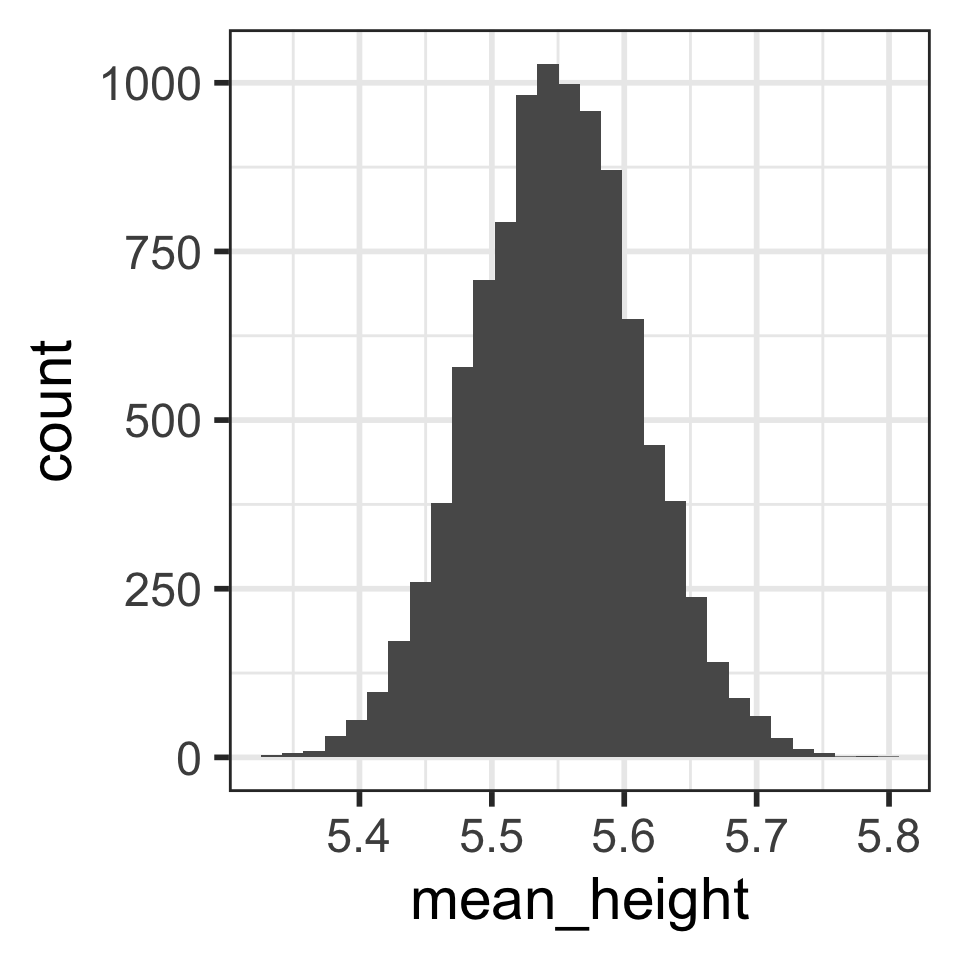
Calculate the mean and SD of the 10,000 mean heights from the 10,000 samples:
stats_means_hght_samp_n30_rep10000<-
means_hght_samp_n30_rep10000 %>%
summarise(
mean_mean_height=mean(mean_height),
sd_mean_height = sd(mean_height)
)
stats_means_hght_samp_n30_rep10000# A tibble: 1 × 2
mean_mean_height sd_mean_height
<dbl> <dbl>
1 5.55 0.0623Is the mean of the means close to the “center” of the distribution?
Compare distributions of 10,000 sample mean heights when n = 5 (left) vs. n = 30 (right)
How are the center, shape, and spread similar and/or different?
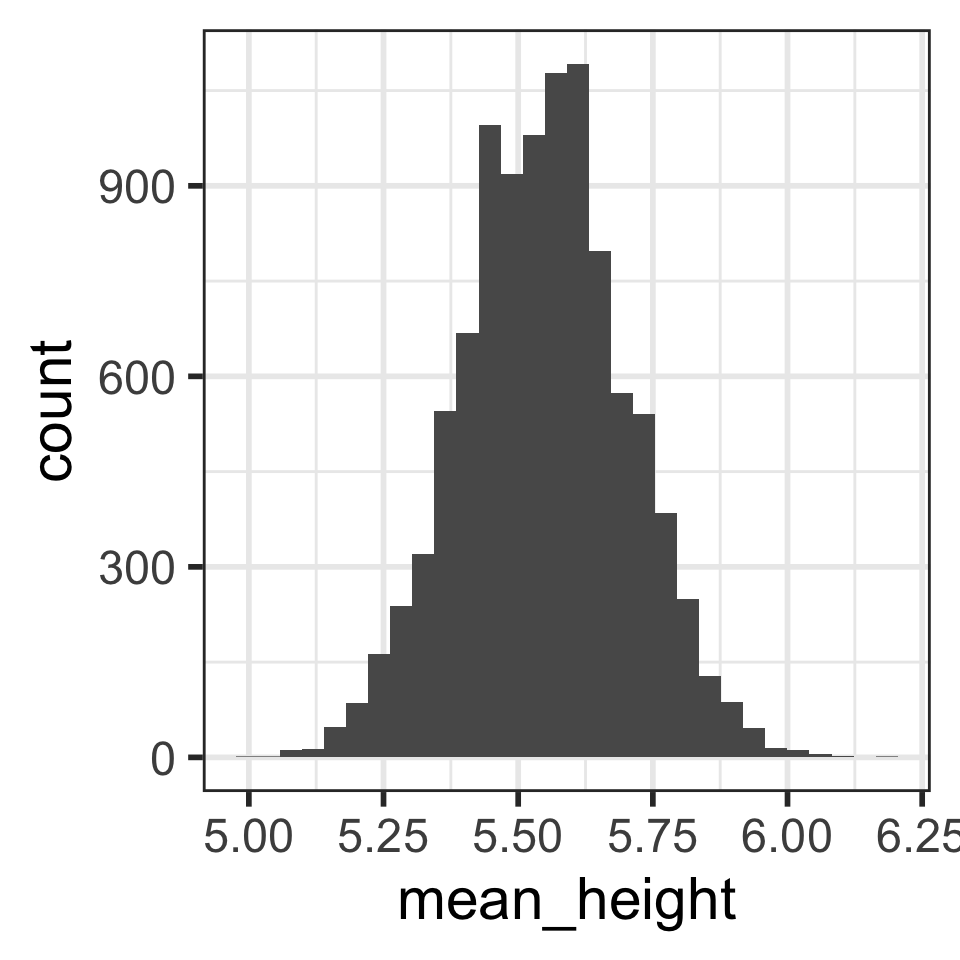
# A tibble: 1 × 2
mean_mean_height sd_mean_height
<dbl> <dbl>
1 5.55 0.153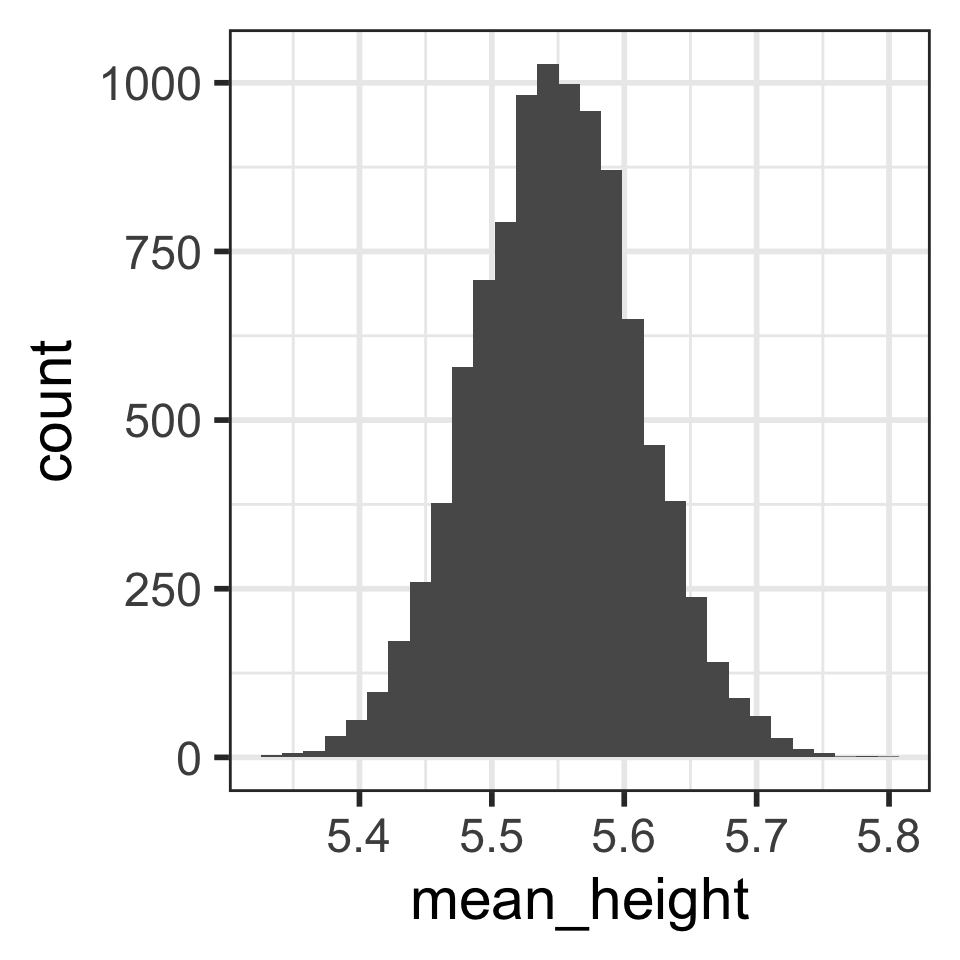
# A tibble: 1 × 2
mean_mean_height sd_mean_height
<dbl> <dbl>
1 5.55 0.0623Sampling high schoolers’ weights
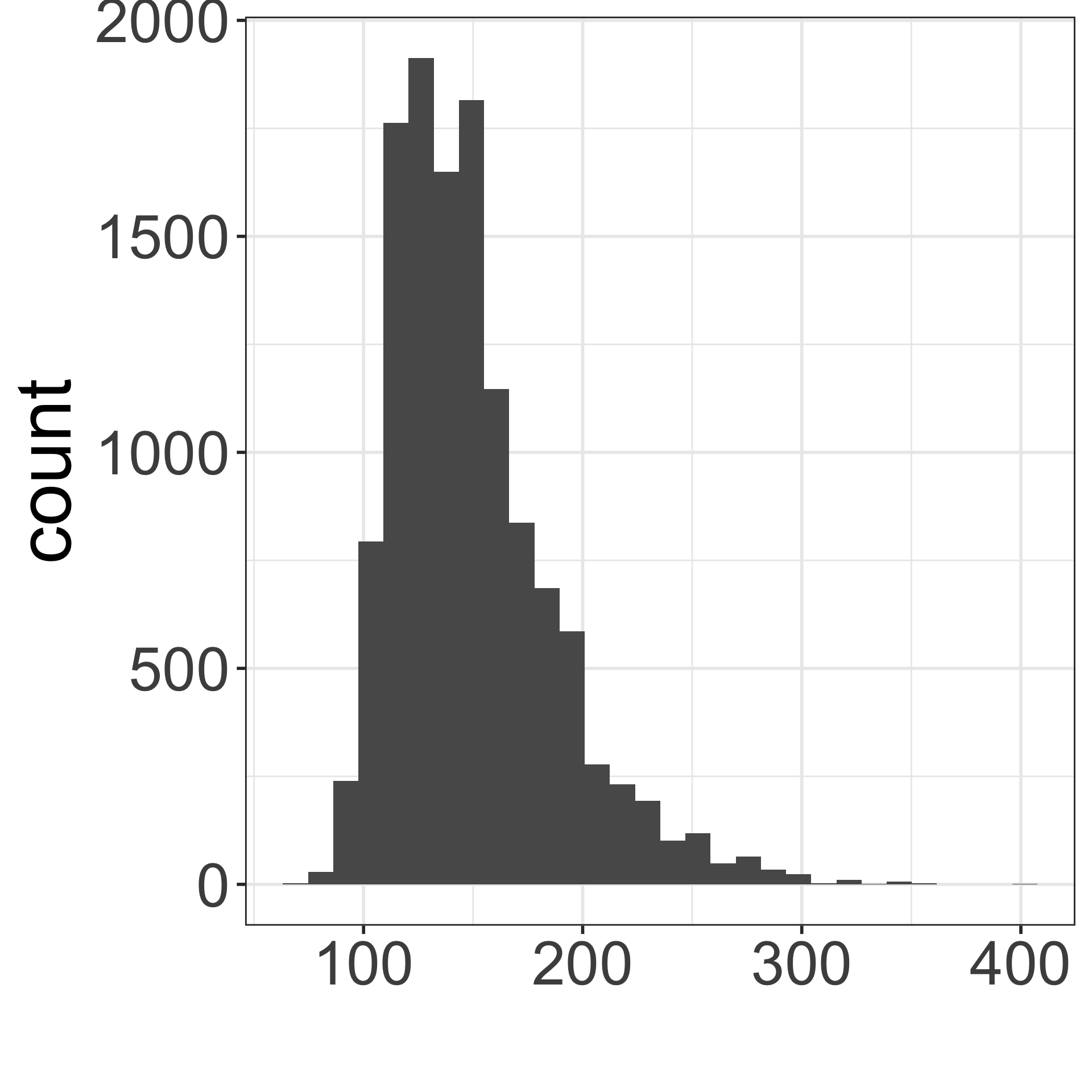
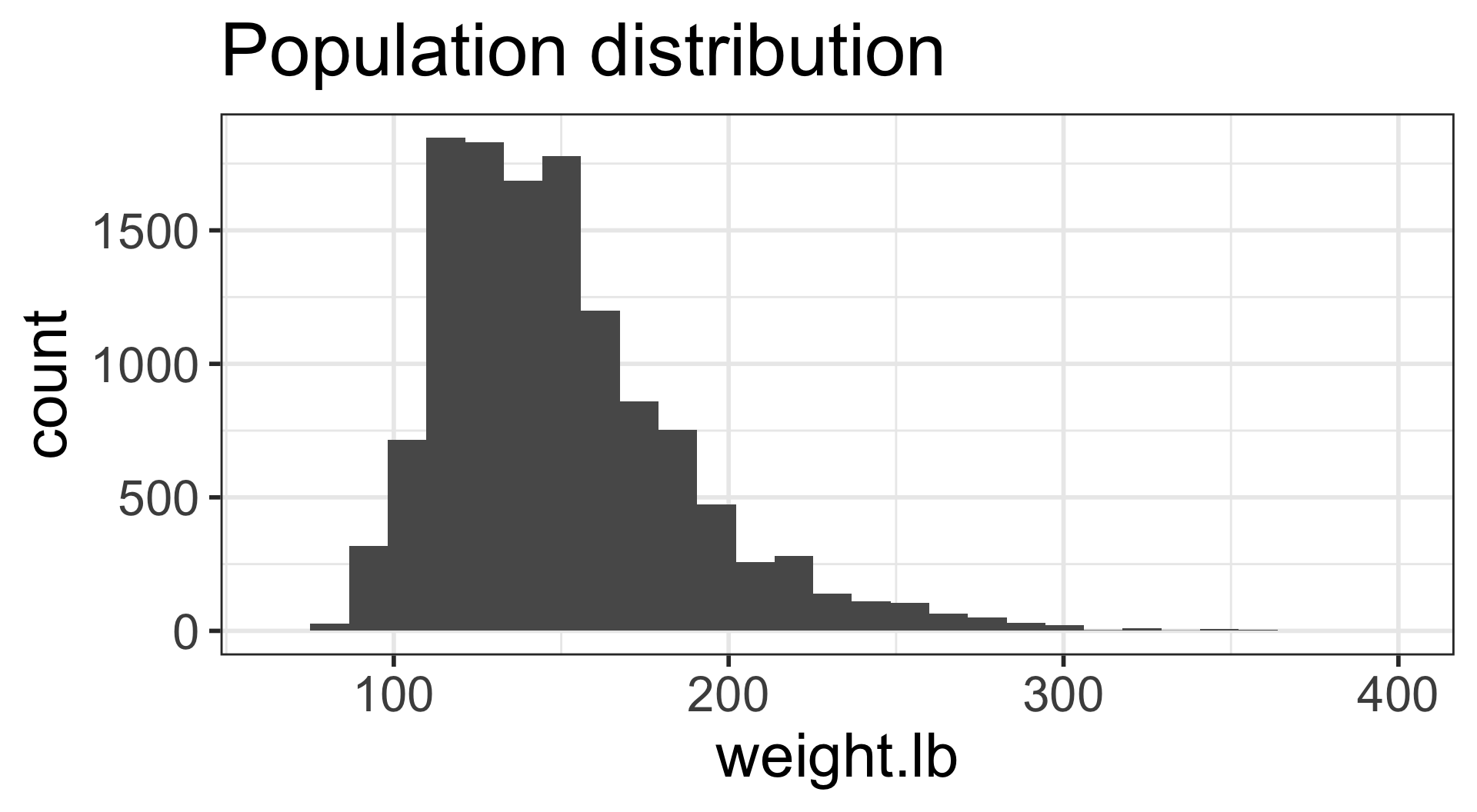
Which figure is which?
- Population distribution of weights
- Sampling distribution of mean weights when \(n=5\)
- Sampling distribution of mean weights when \(n=30\).
A
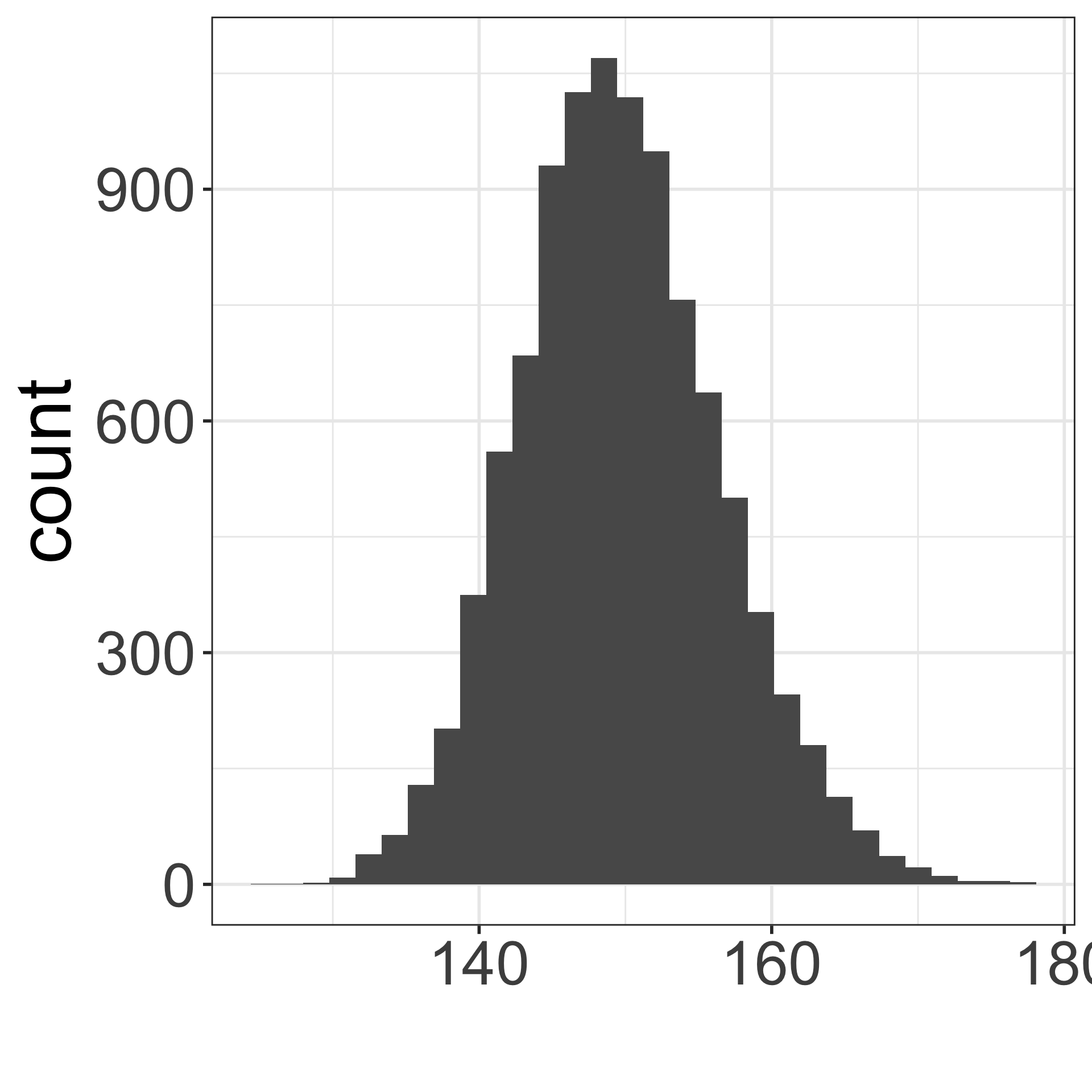
B
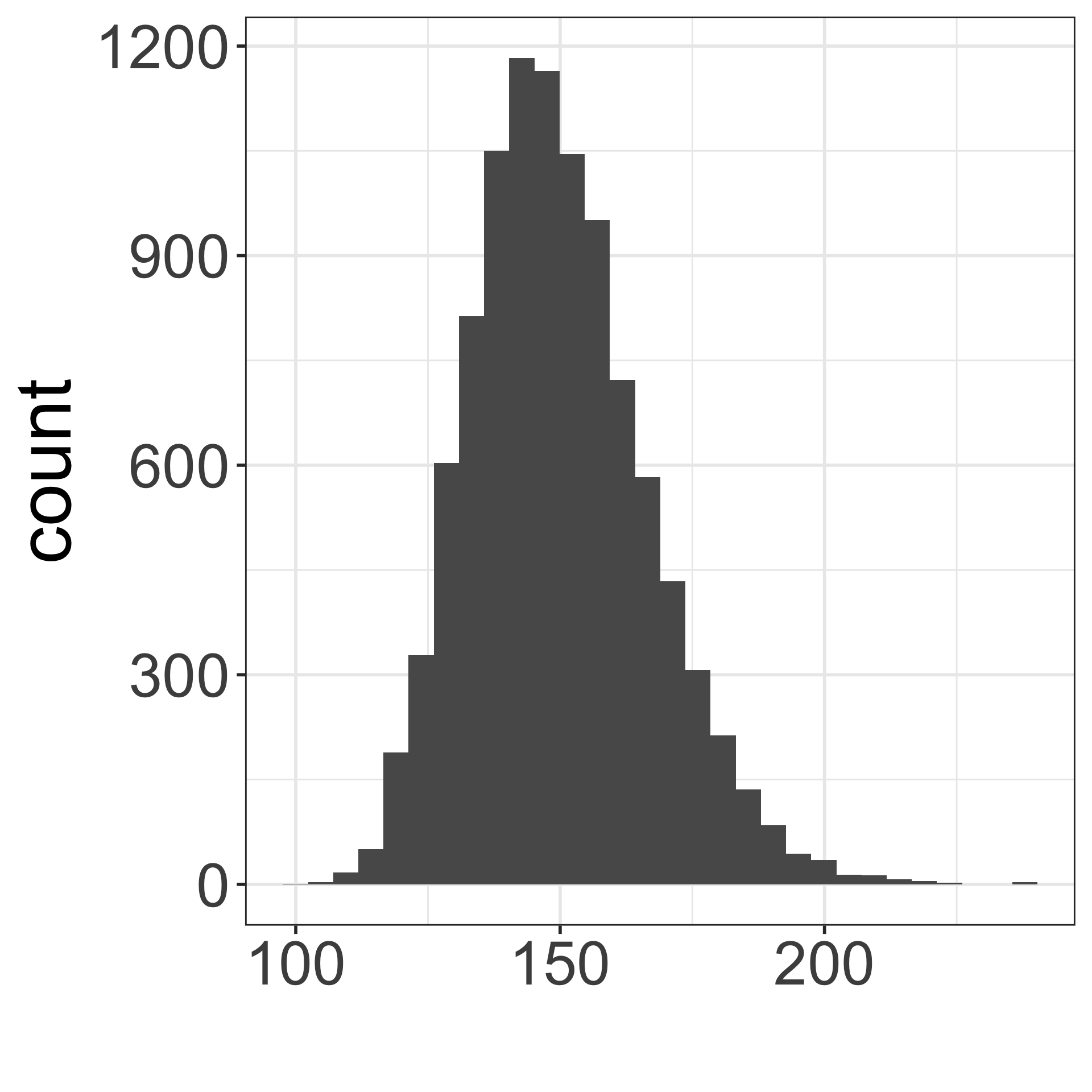
C
The sampling distribution of the mean
The sampling distribution of the mean is the distribution of sample means calculated from repeated random samples of the same size from the same population
Our simulations show approximations of the sampling distribution of the mean for various sample sizes
The theoretical sampling distribution is based on all possible samples of a given sample size \(n\).

The cutest statistics video on YouTube
- Bunnies, Dragons and the ‘Normal’ World: Central Limit Theorem
- Creature Cast from the New York Times
- https://www.youtube.com/watch?v=jvoxEYmQHNM&feature=youtu.be

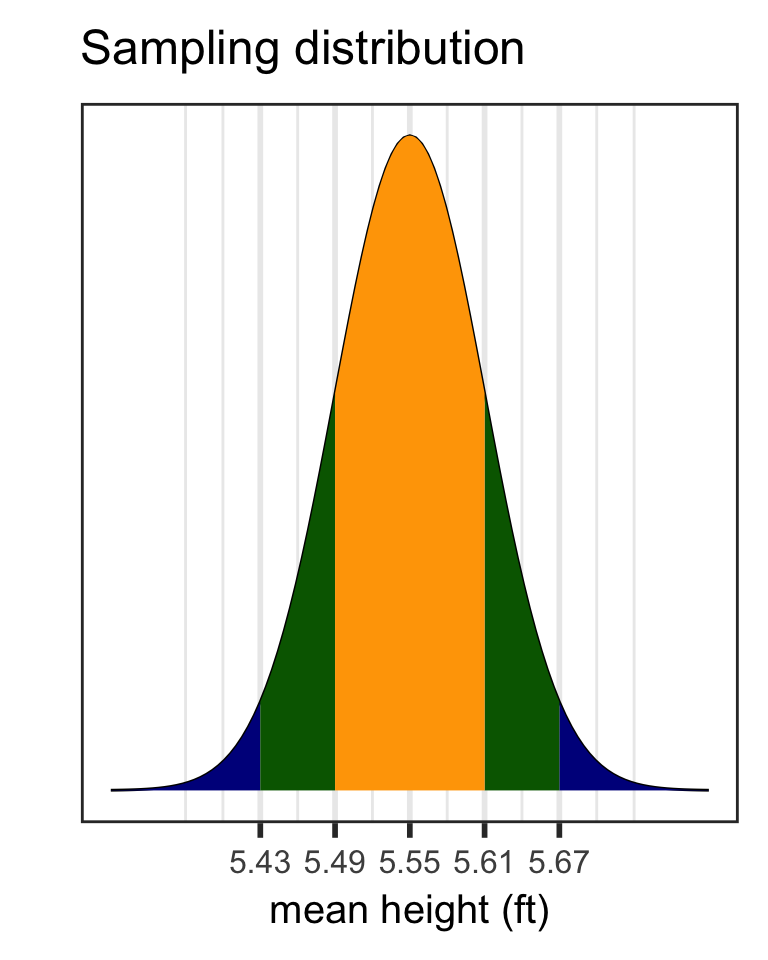
Sampling distribution of mean heights when n = 30 (1/2)
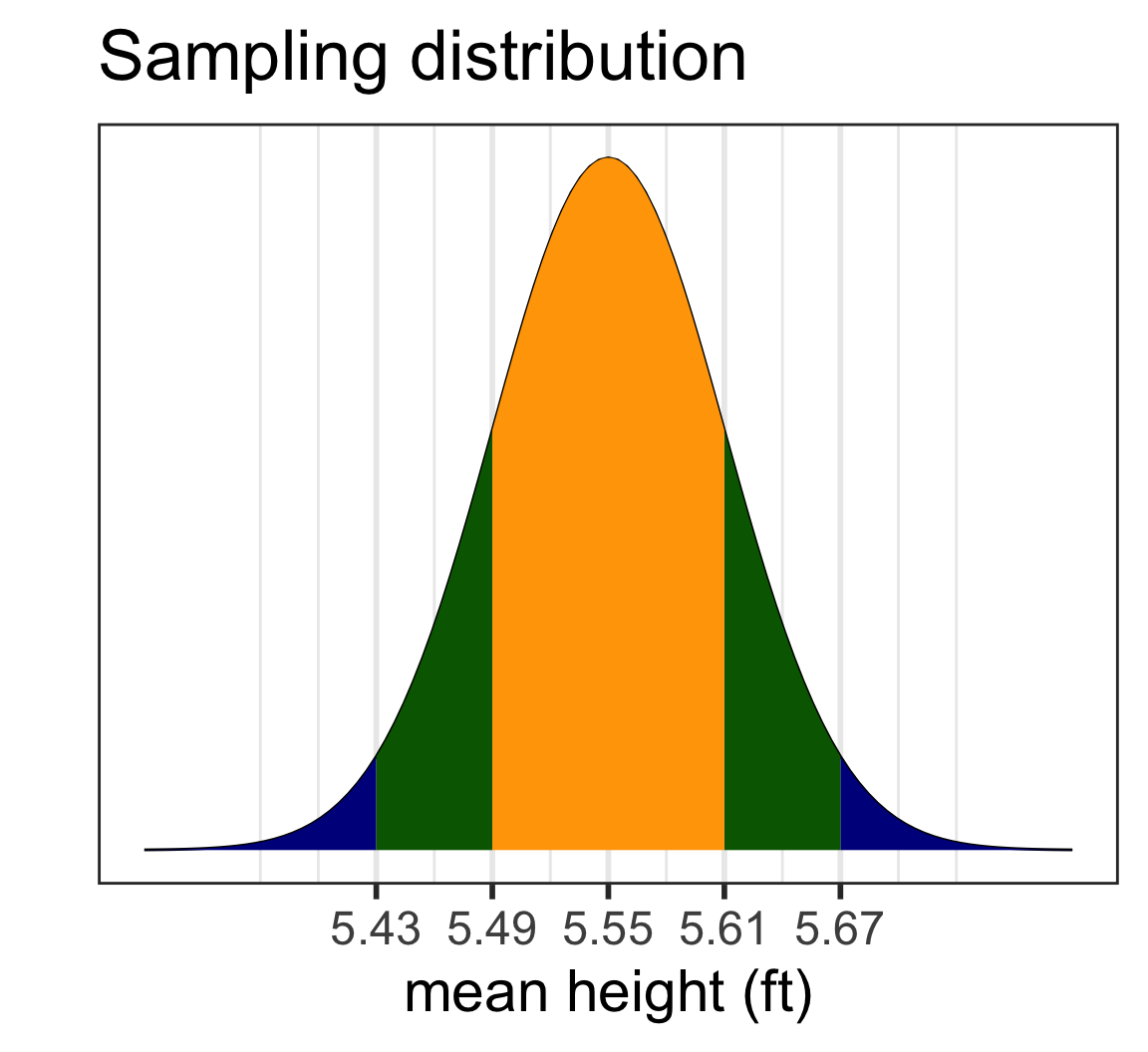
Sampling distribution of mean heights when n = 30 (2/2)
Mean and SD of population:
[1] 5.548691[1] 0.3434949[1] 0.06271331Mean and SD of simulated sampling distribution: