Day 3: Data visualization
BSTA 511/611, OHSU
2023-10-04
Goals for today
- Exploratory Data Analysis (EDA) (Sections 1.4, 1.5, 1.6, 1.7.1)
- Data visualization with ggplot
- numerical & categorical variables, and relationships between variables
- Summarizing numerical data
- Frequency (two-way) tables
- Data visualization with ggplot
- Some data wrangling techniques along the way

International Day of Women in Statistics and Data Science
Tuesday, October 10, 2022
12 am - 11:59 pm UTC (5pm 10/9 to 4:59 pm 10/10 here)
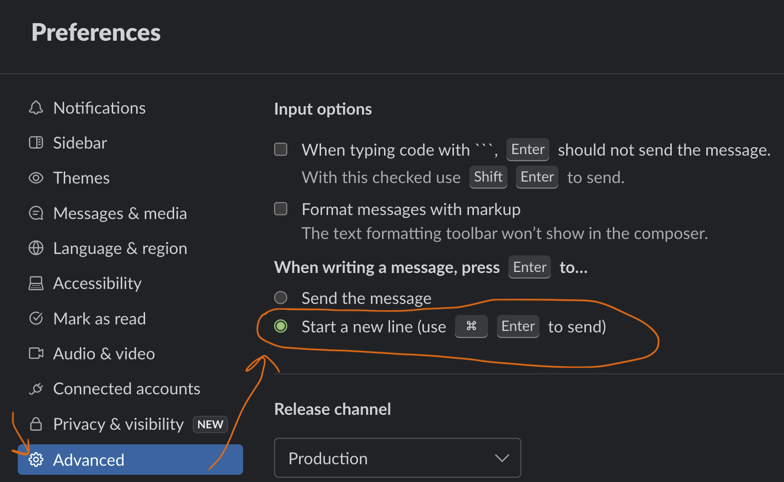
Mimi’s tip of the day: sending messages in Slack
Are you frustrated that Slack sends a message when you press Enter? You can change that!

R Packages
A good analogy for R packages is that they
are like apps you can download onto a mobile phone:

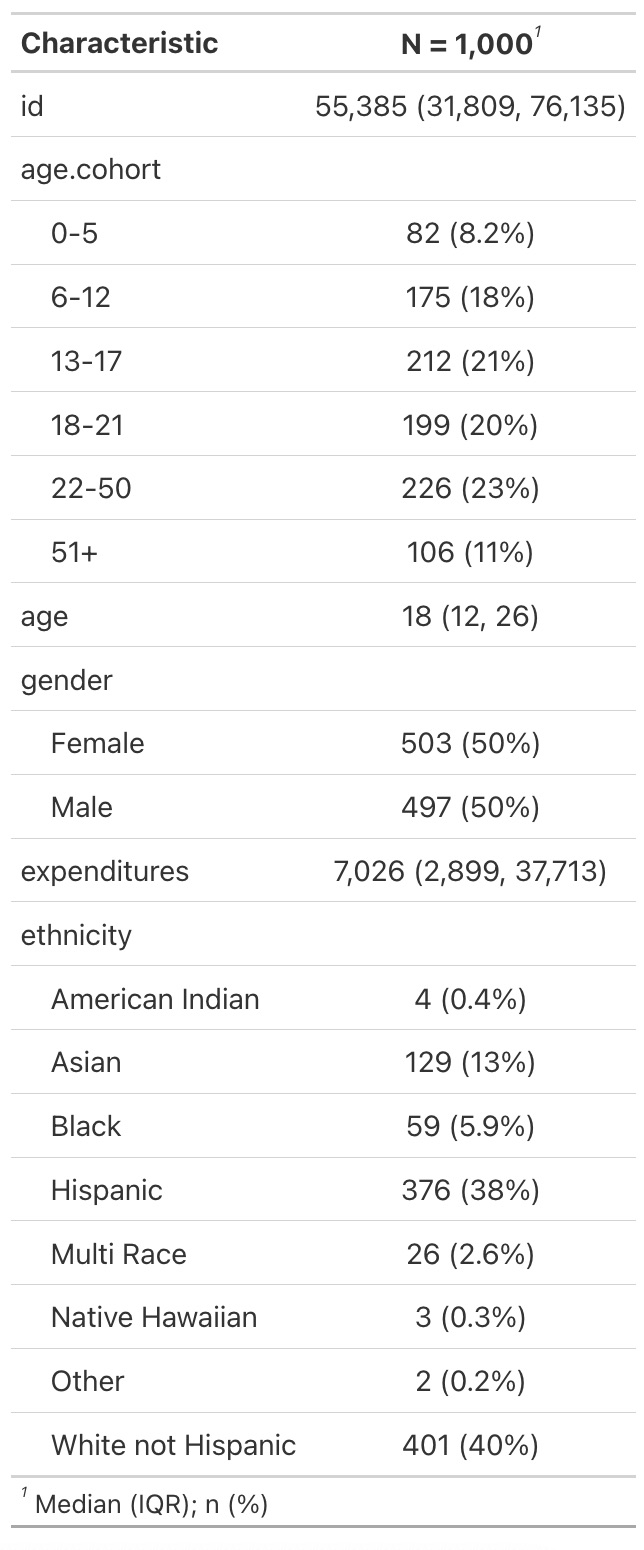
tbl_summary(): summary table
Visualize numerical variables with ggplot


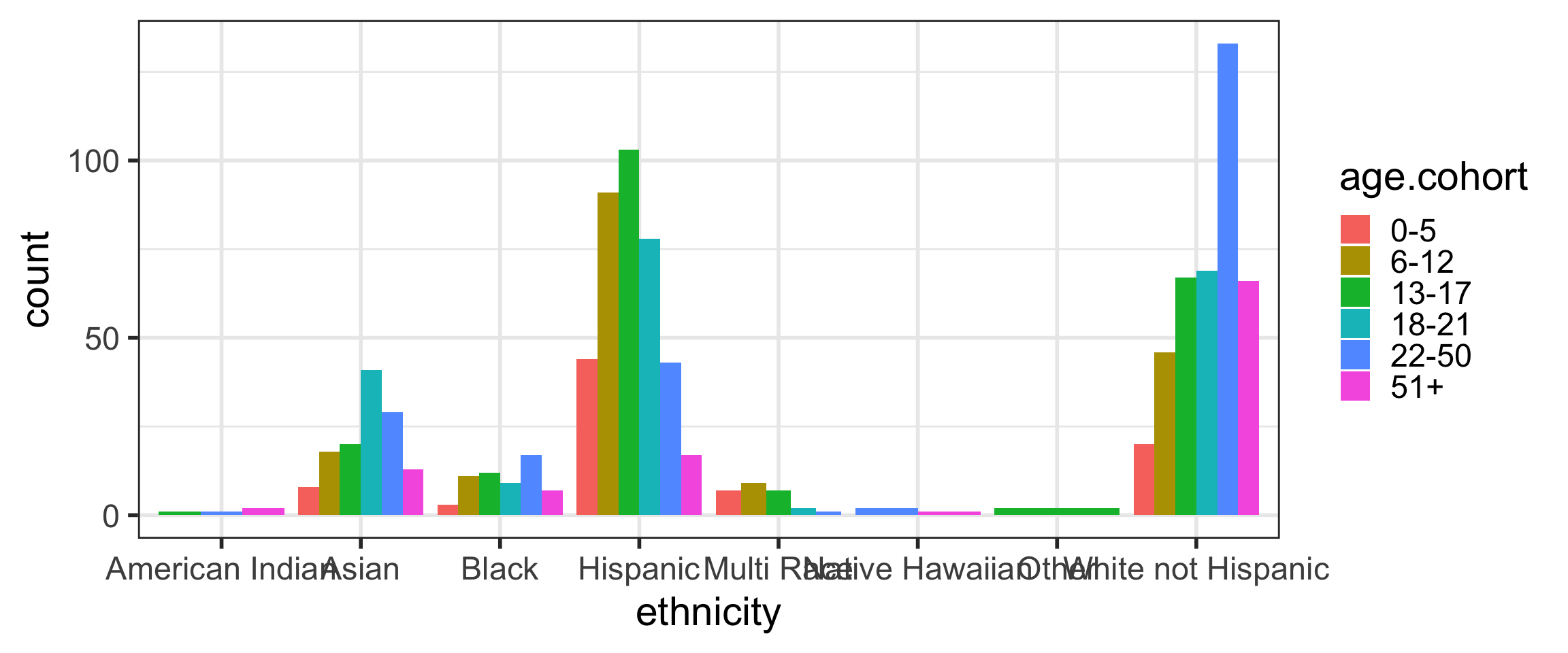
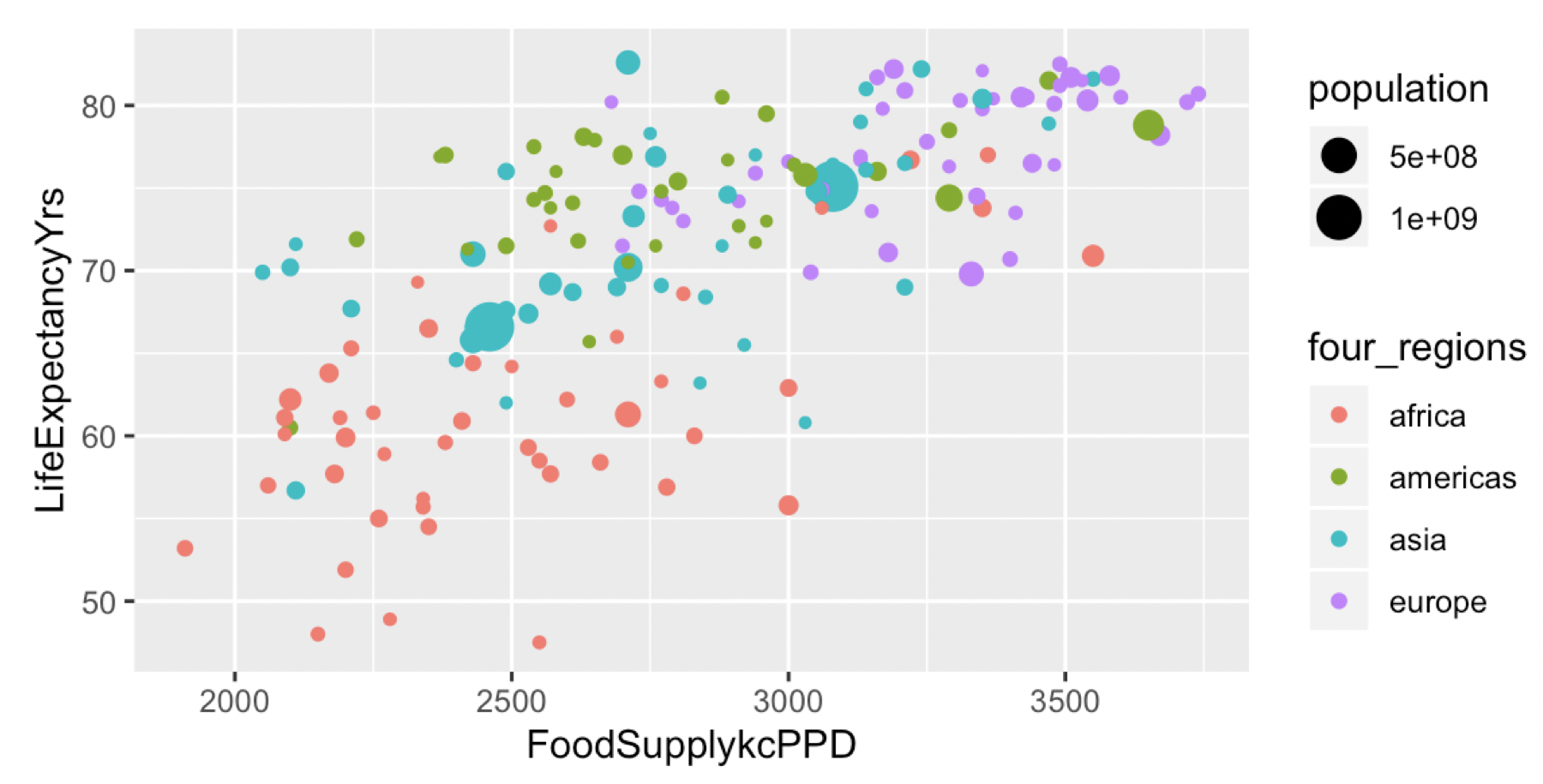
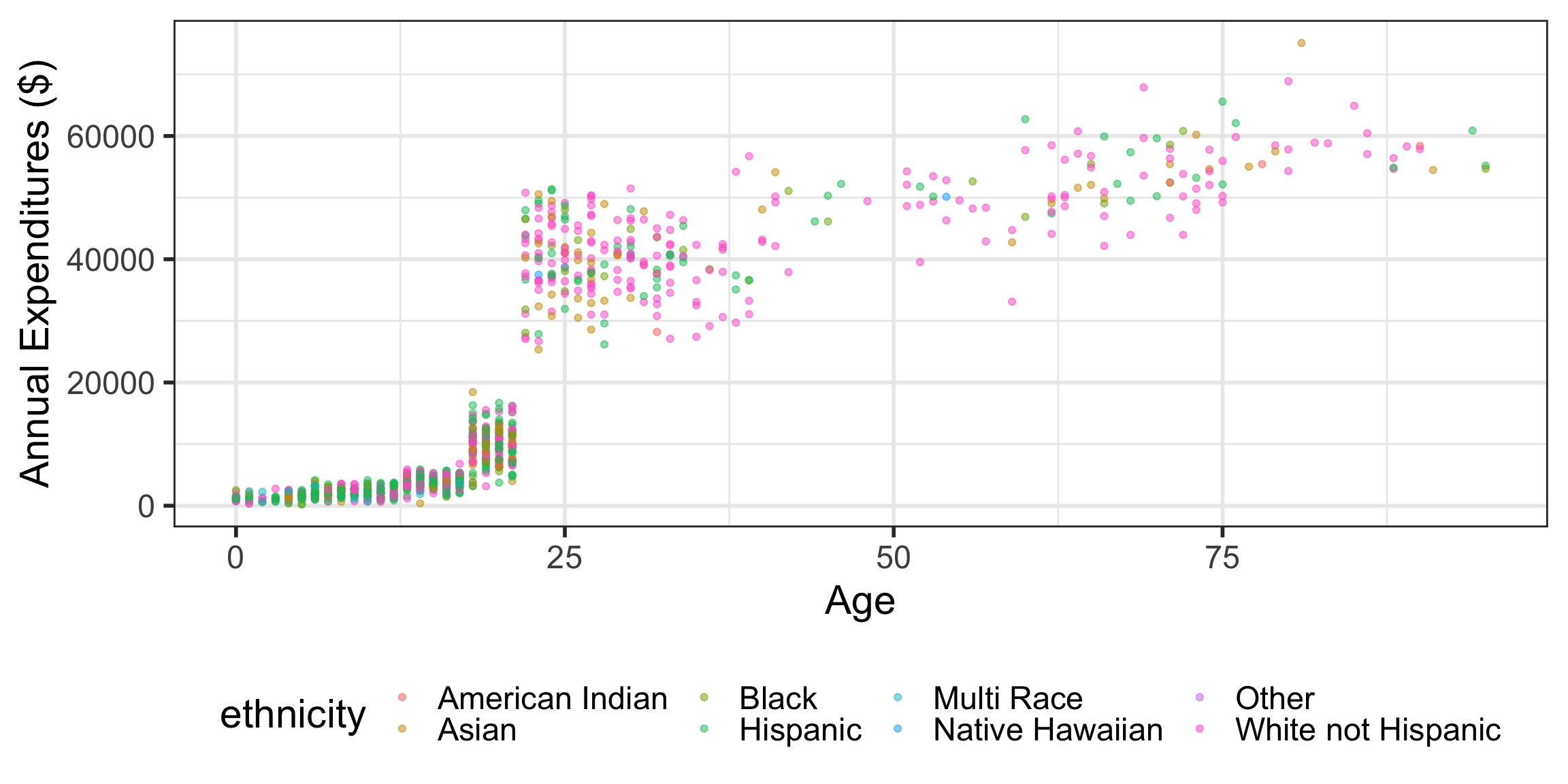
What data (variables) are included in the plot below?
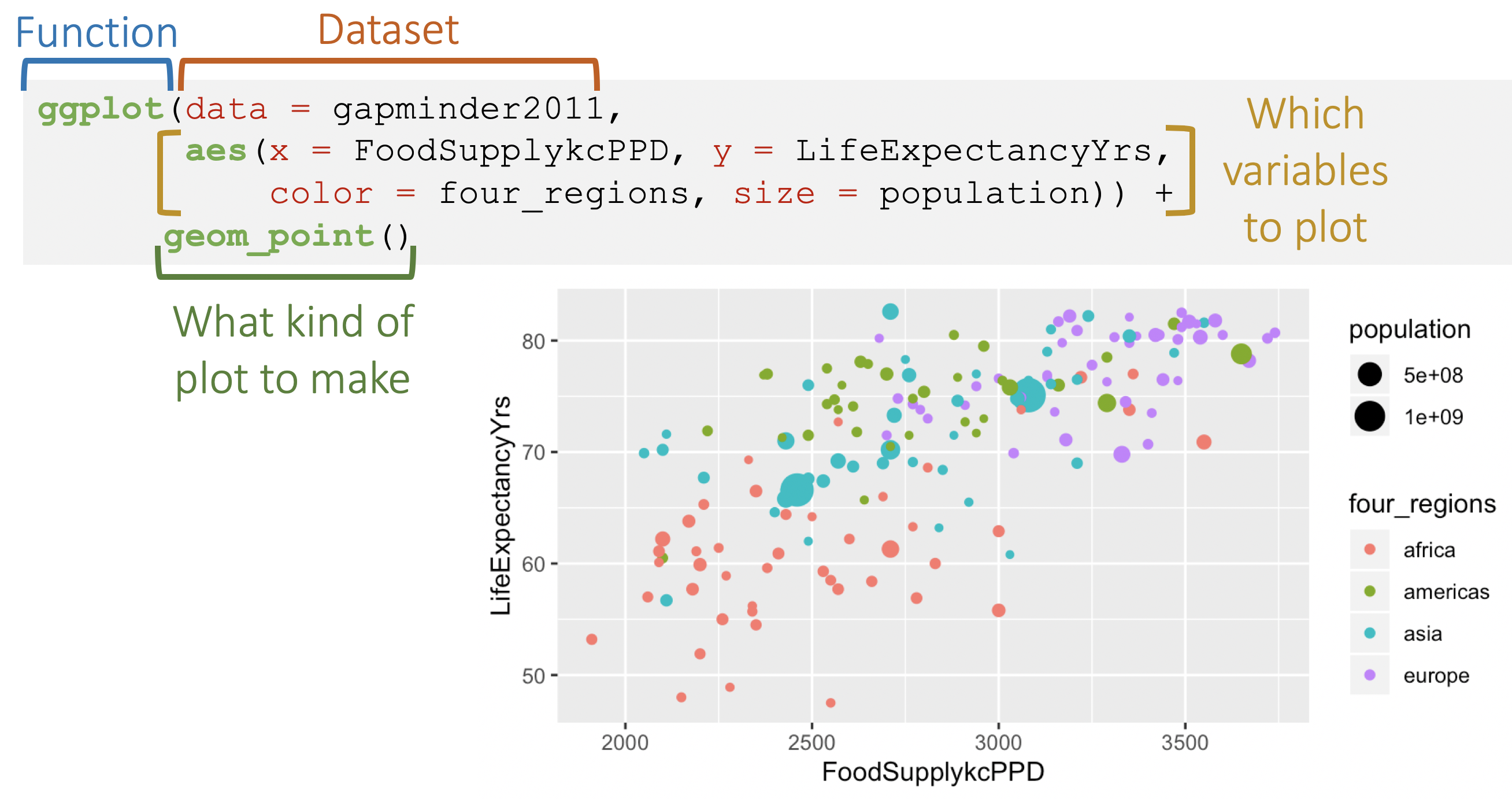
Basics of a ggplot
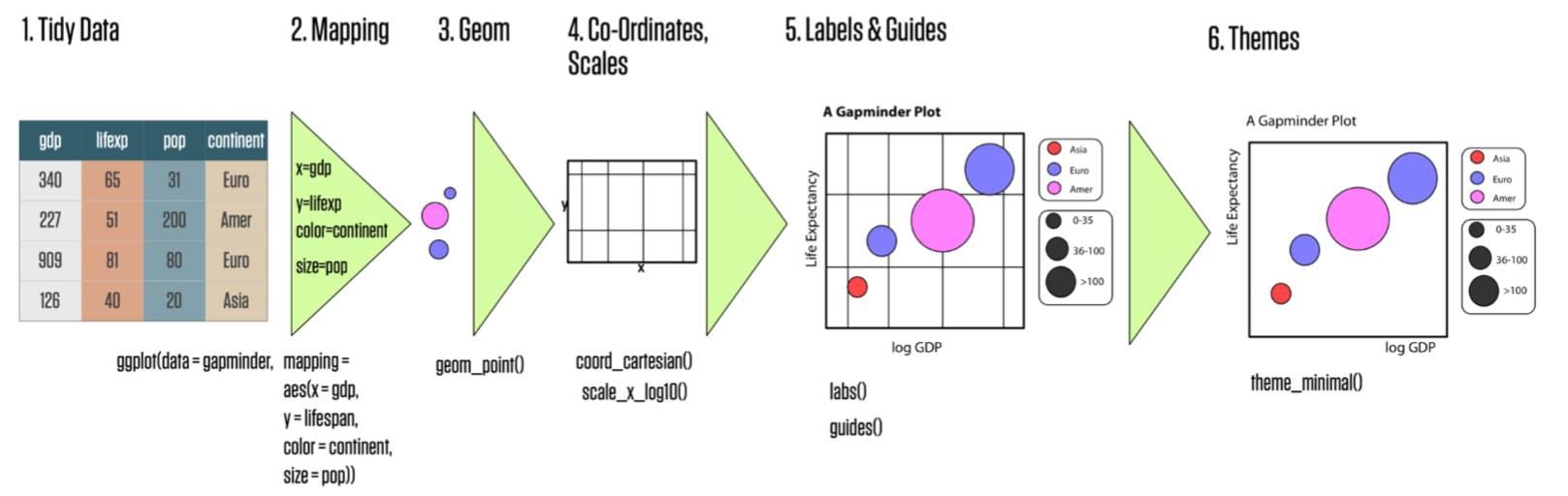
Grammar of ggplot2
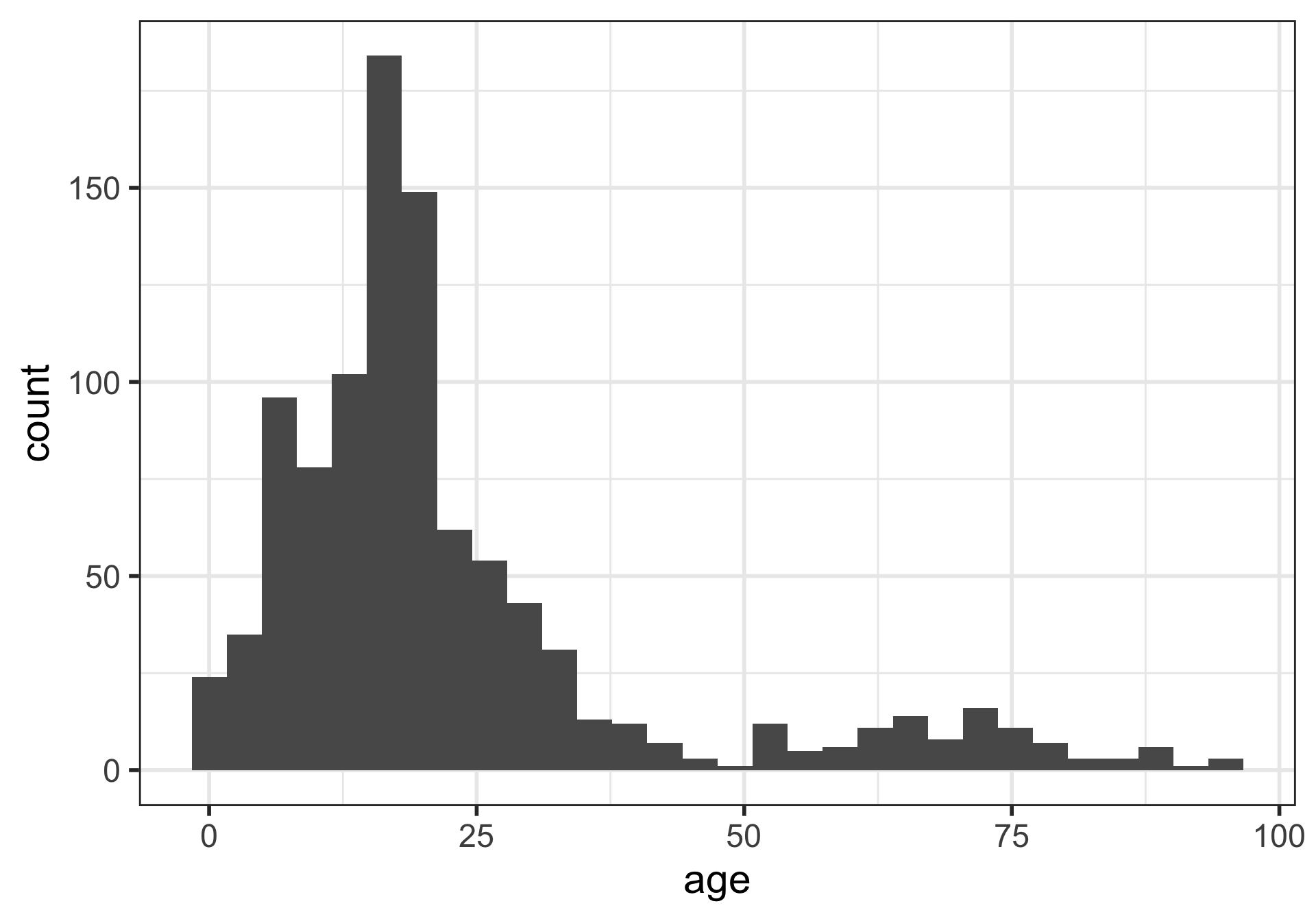
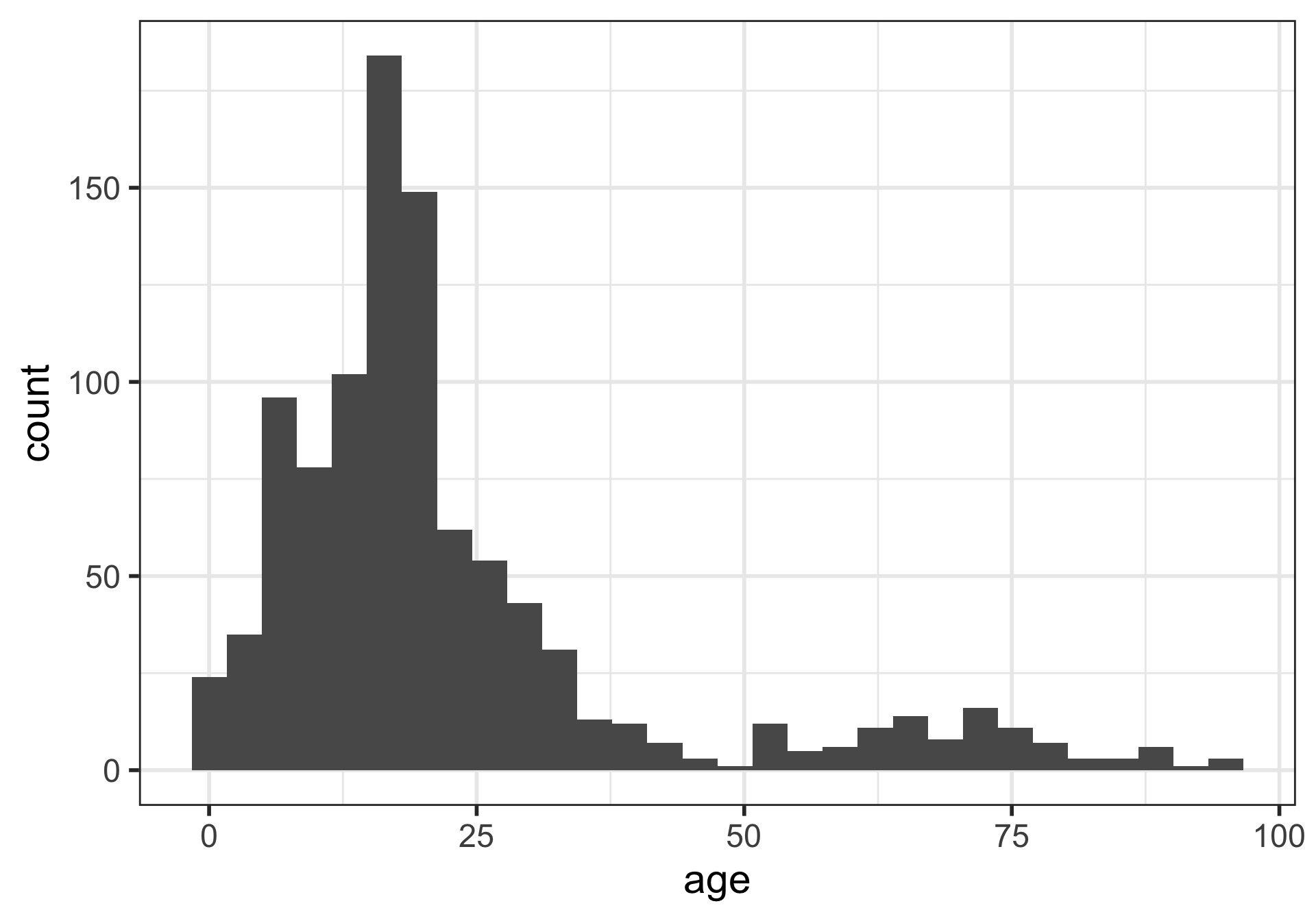
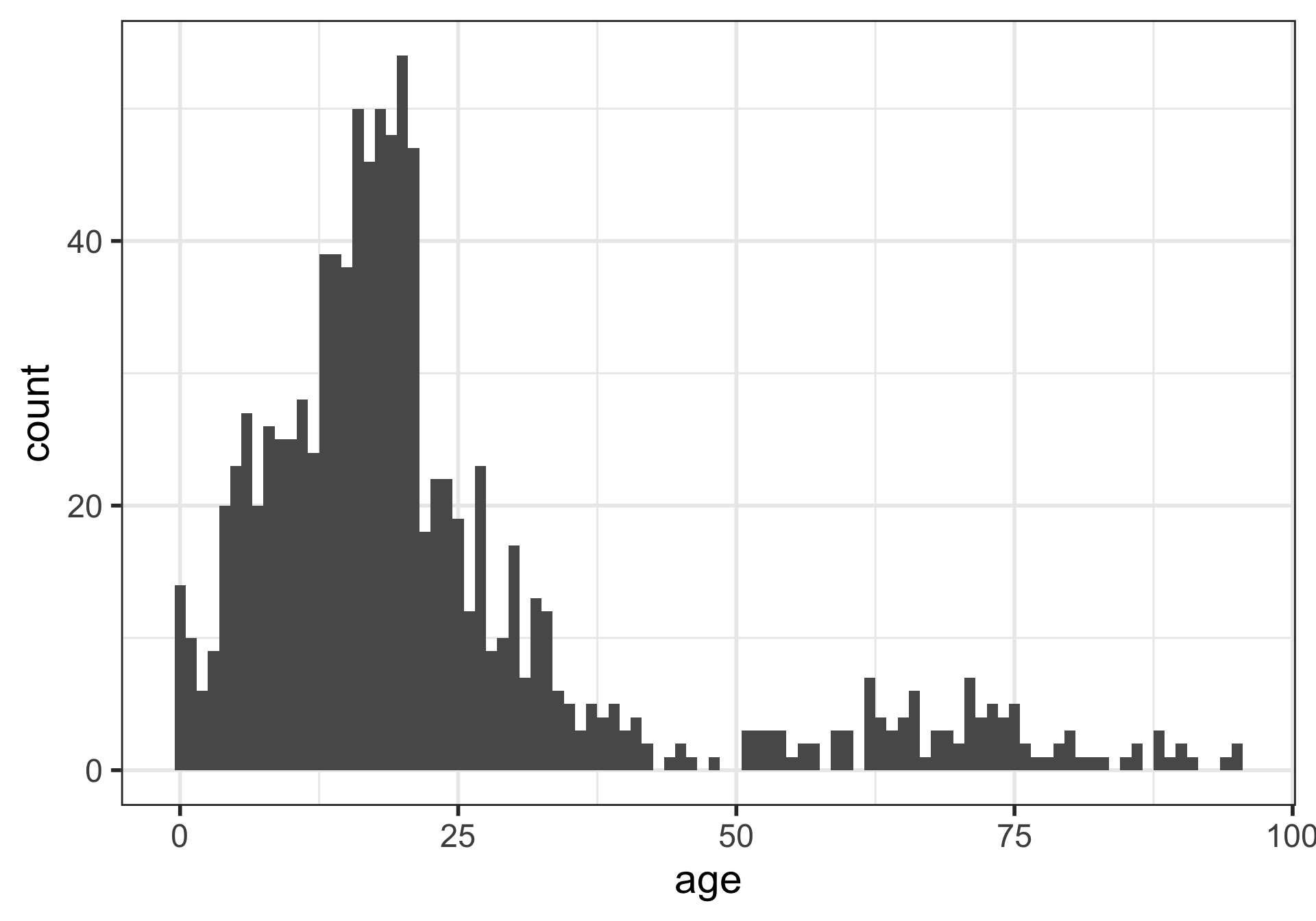
Histograms
What is being measured on the vertical axes?
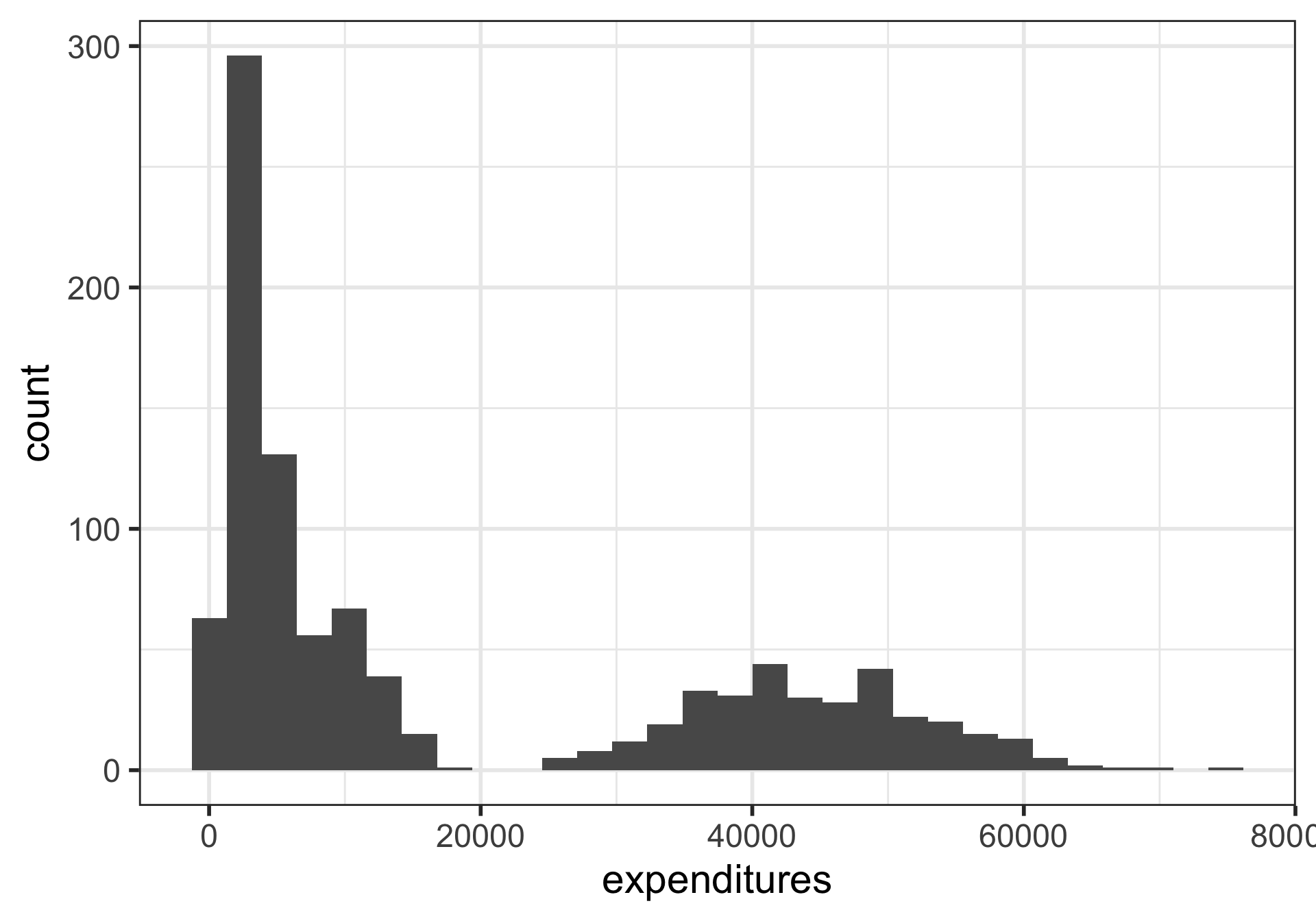
Histograms showing proportions
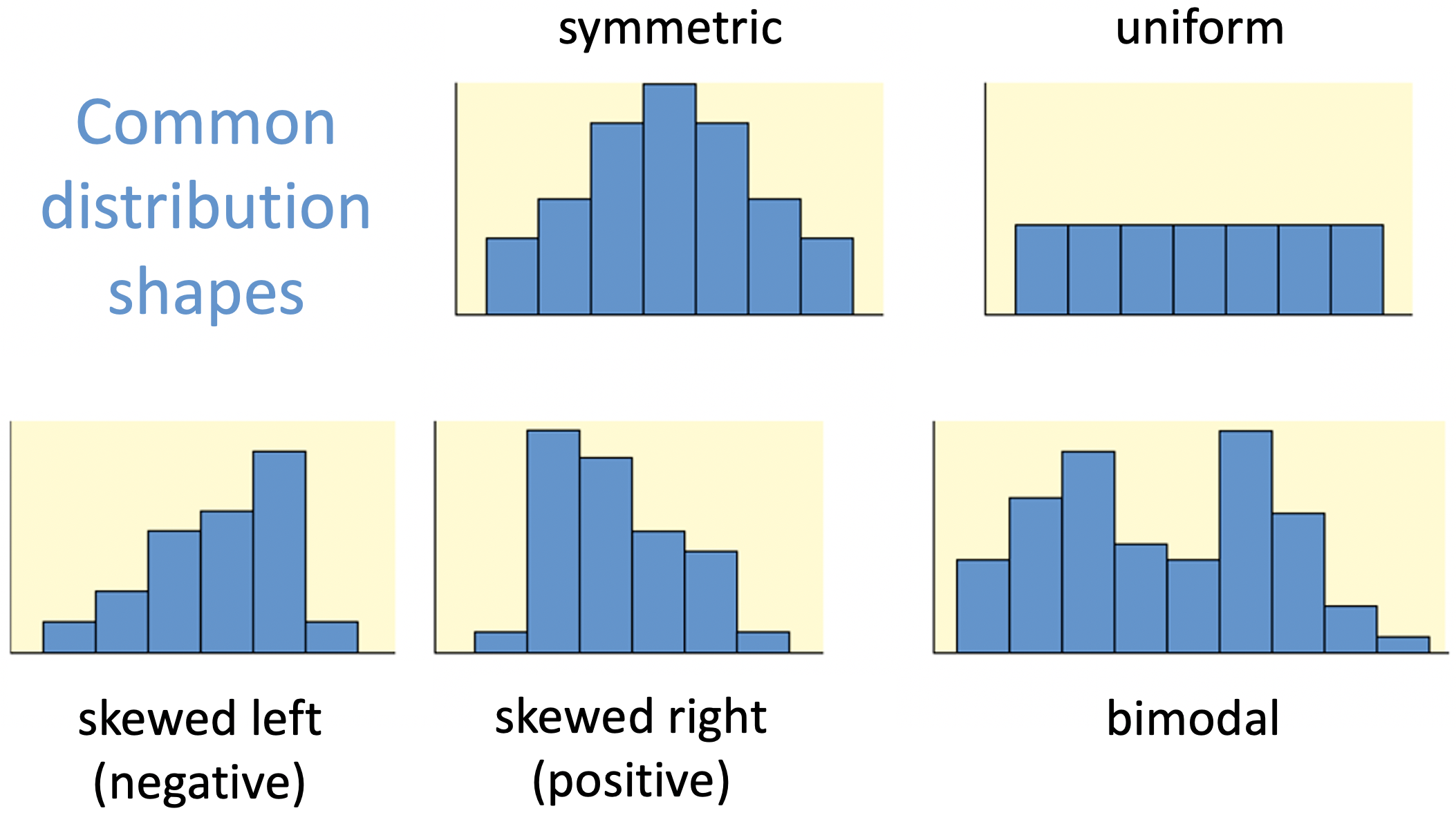
Distribution shapes
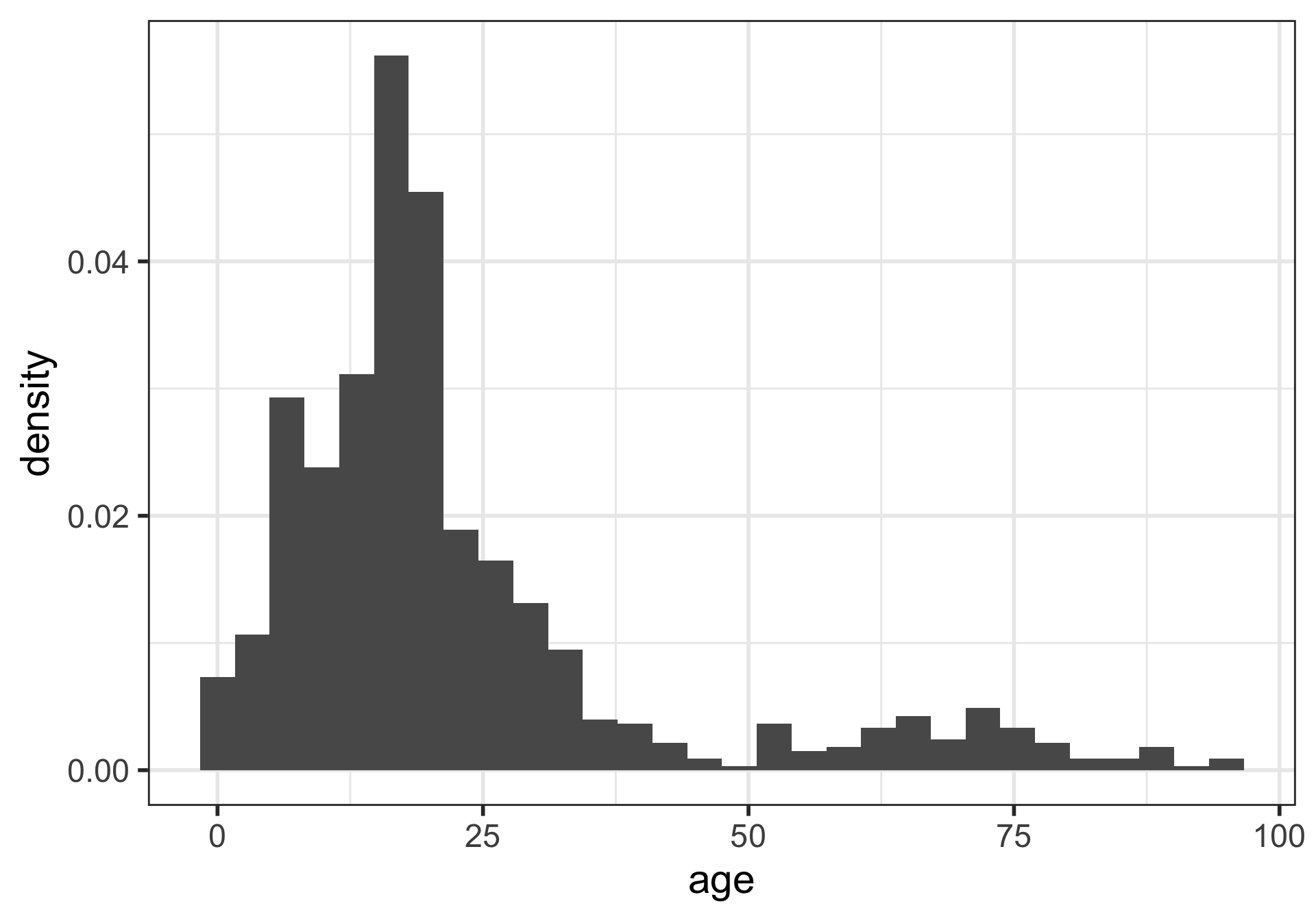
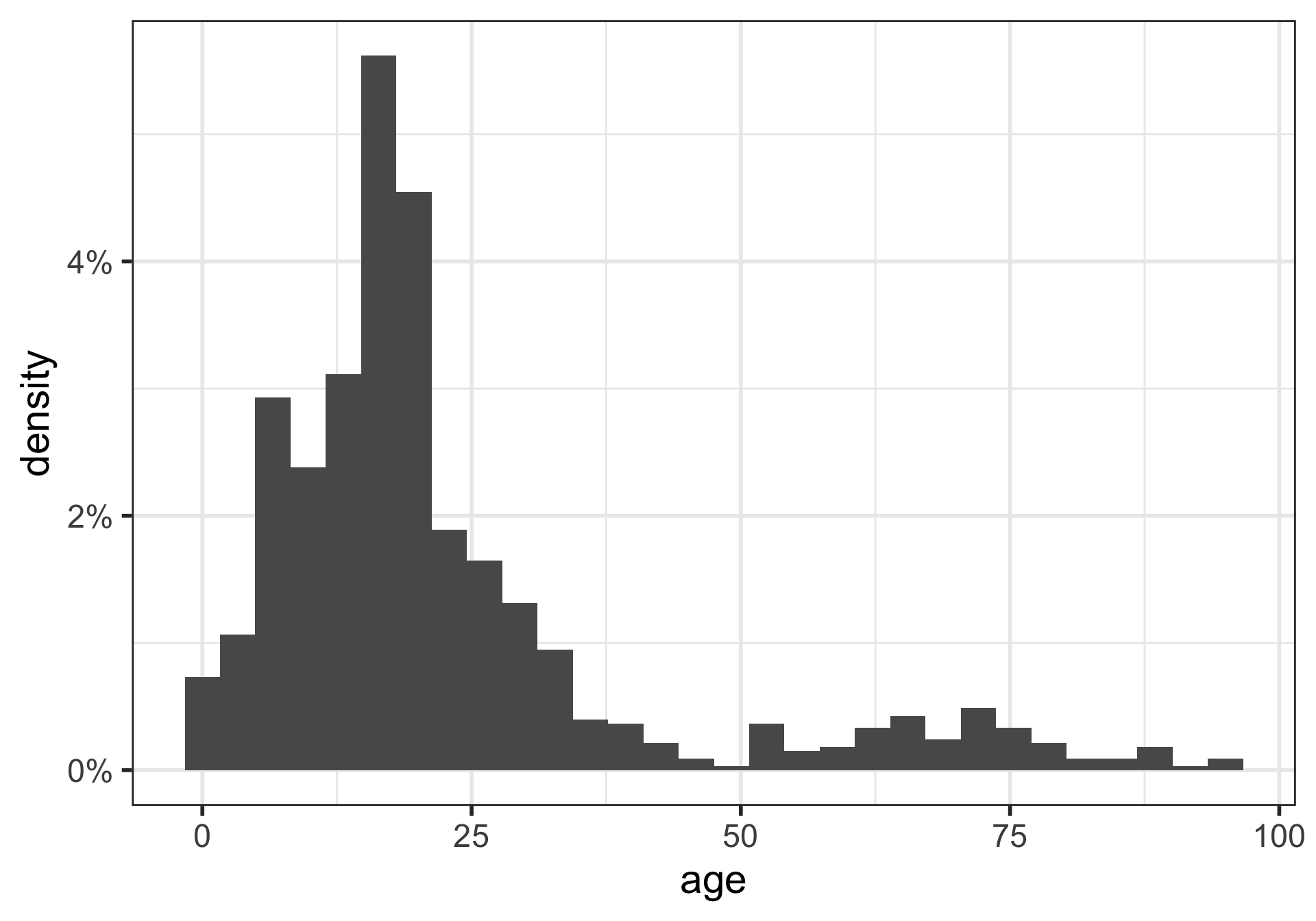
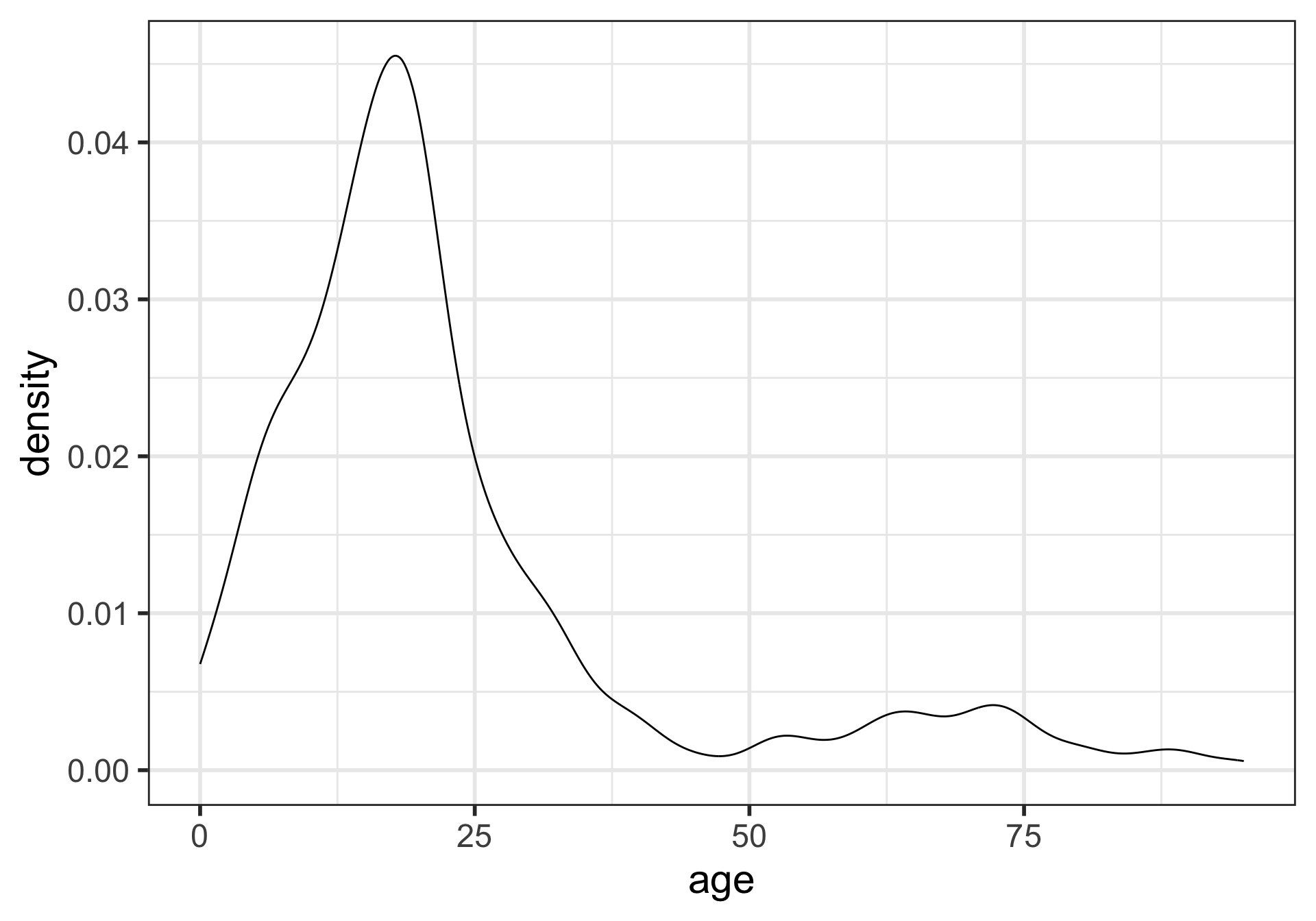
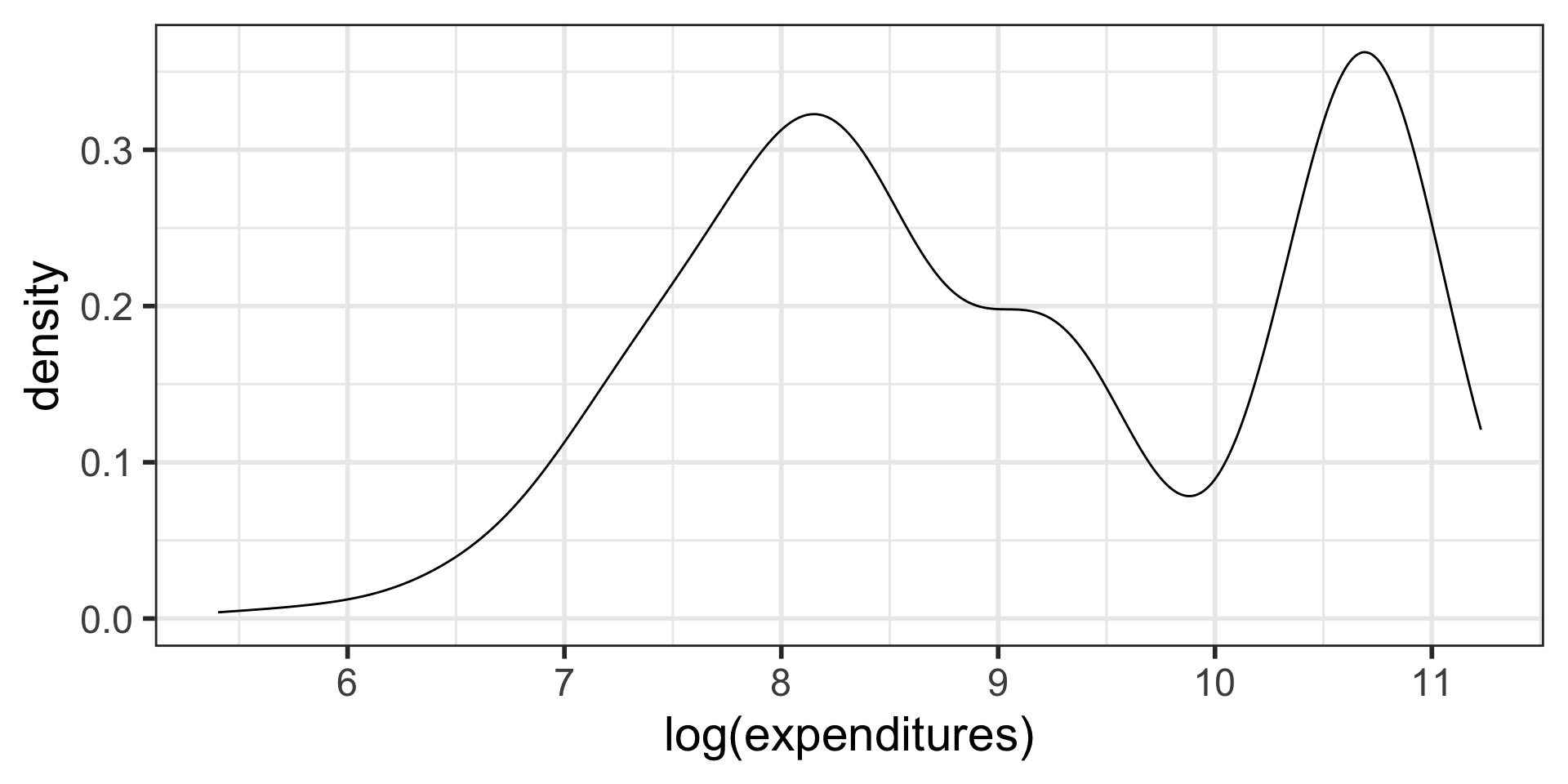
Density plots
What is being measured on the vertical axes?
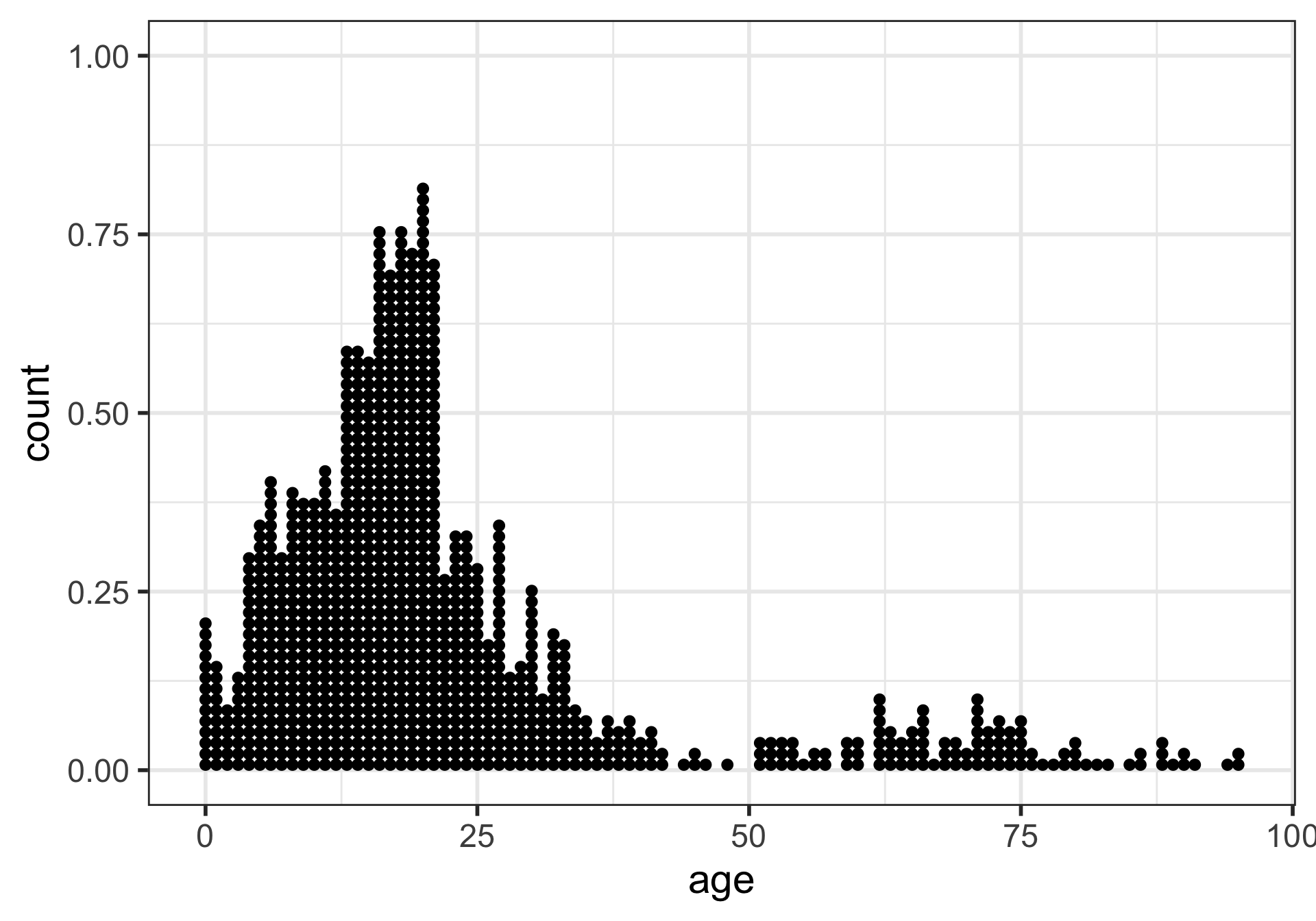
Dot plots
- Better for smaller samples
- What is being measured on the vertical axes?
Boxplots
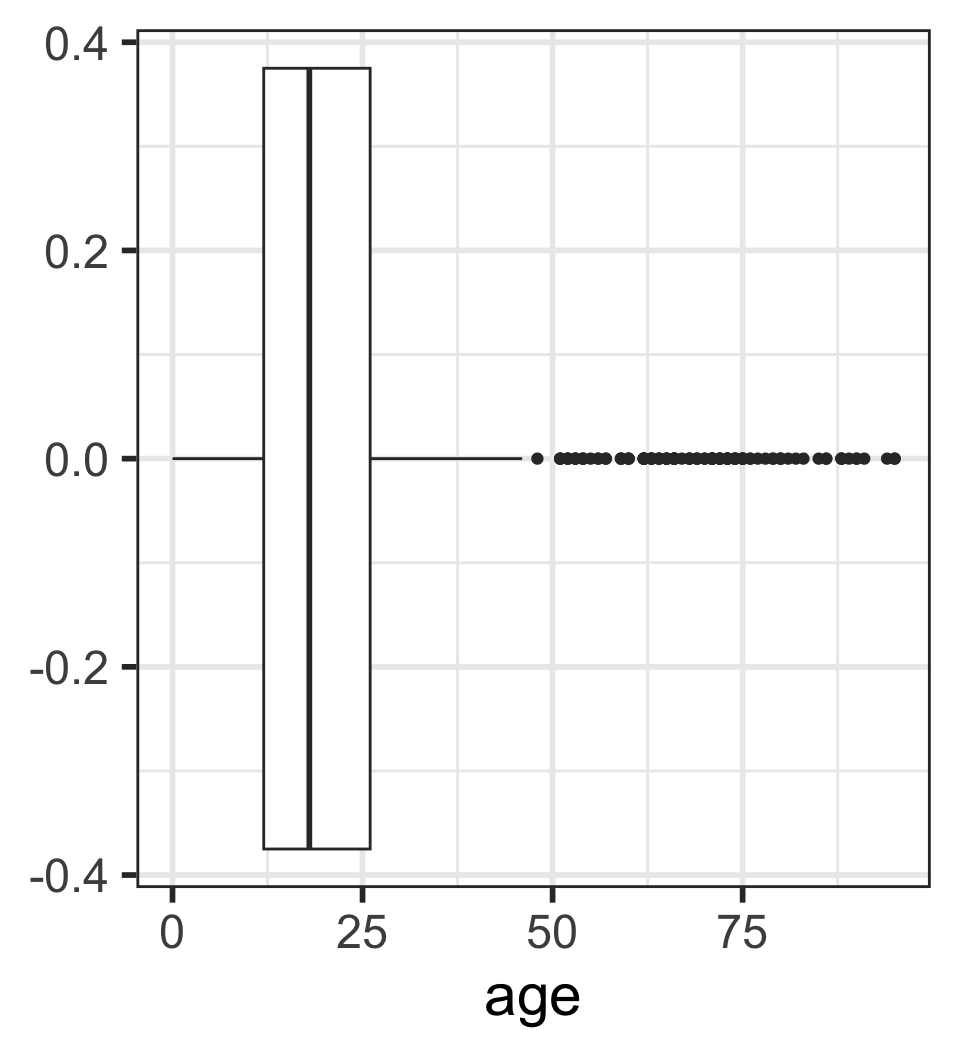
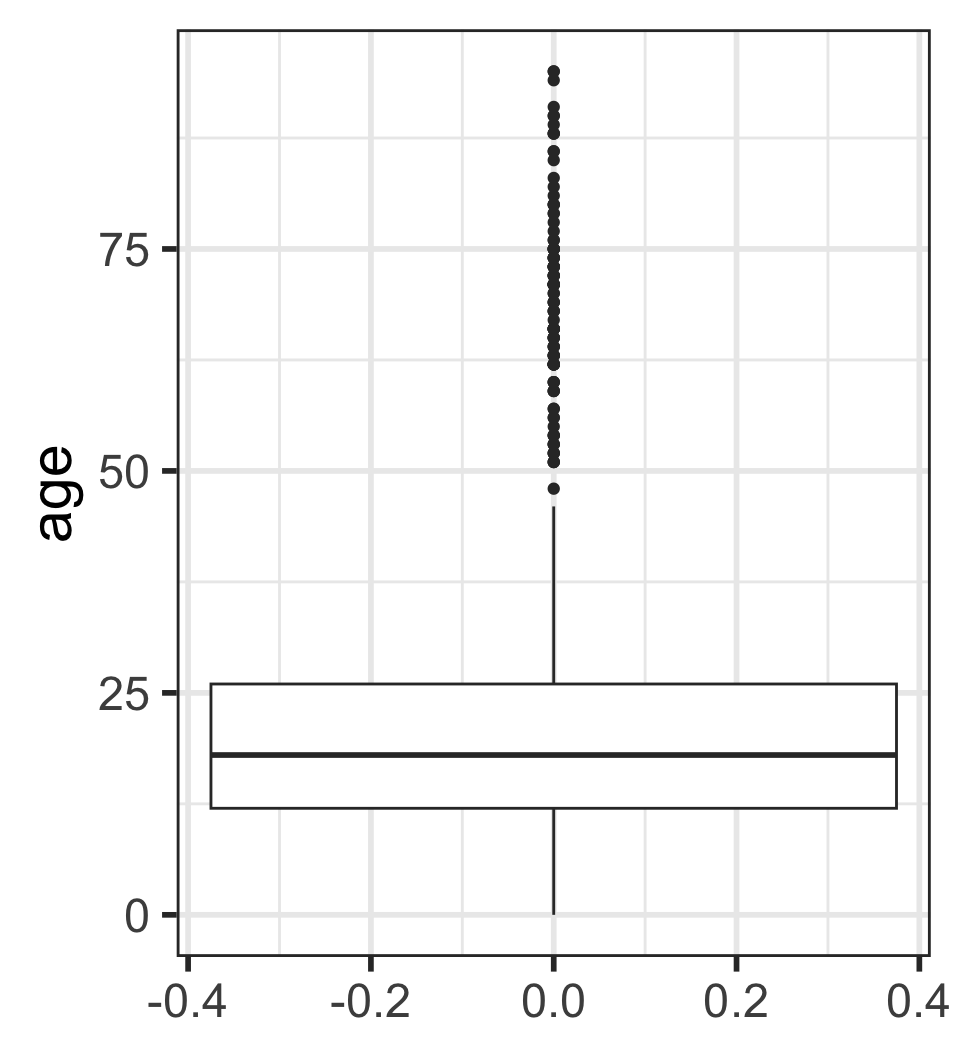
Boxplots: 5 number summary visualization
No outliers: 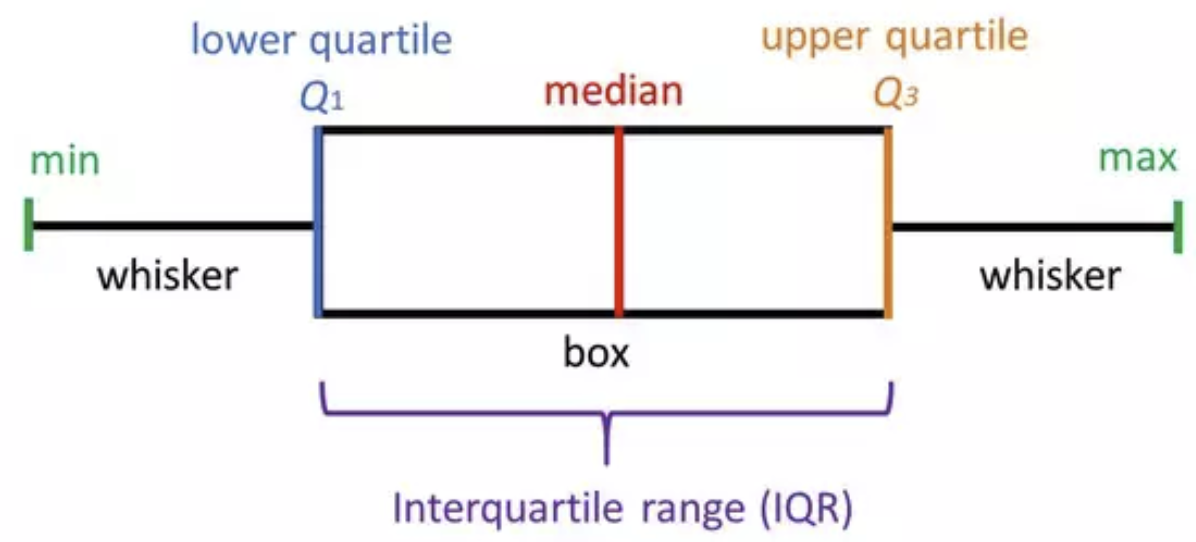
With outliers: 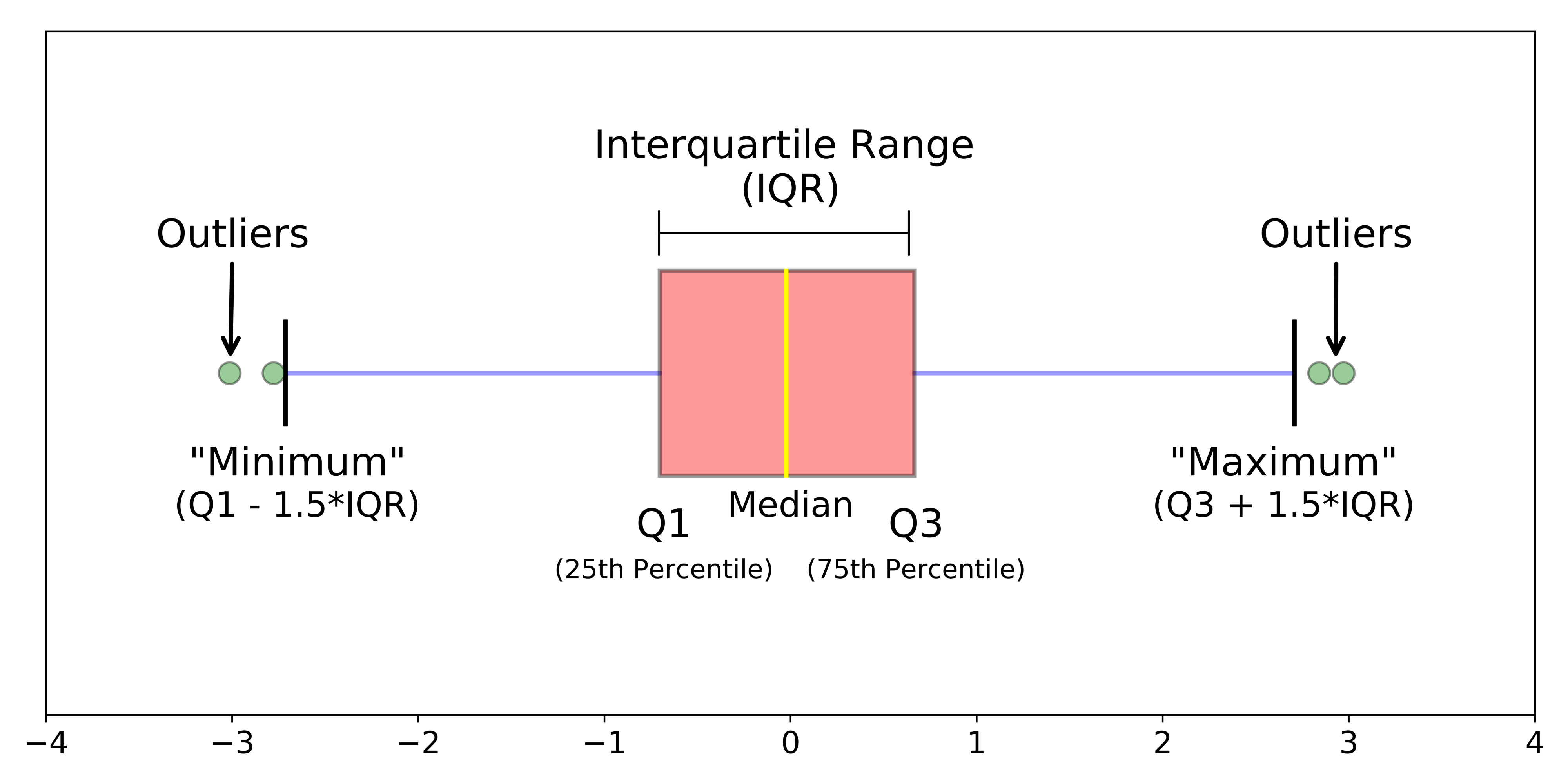
Side-by-side boxplots
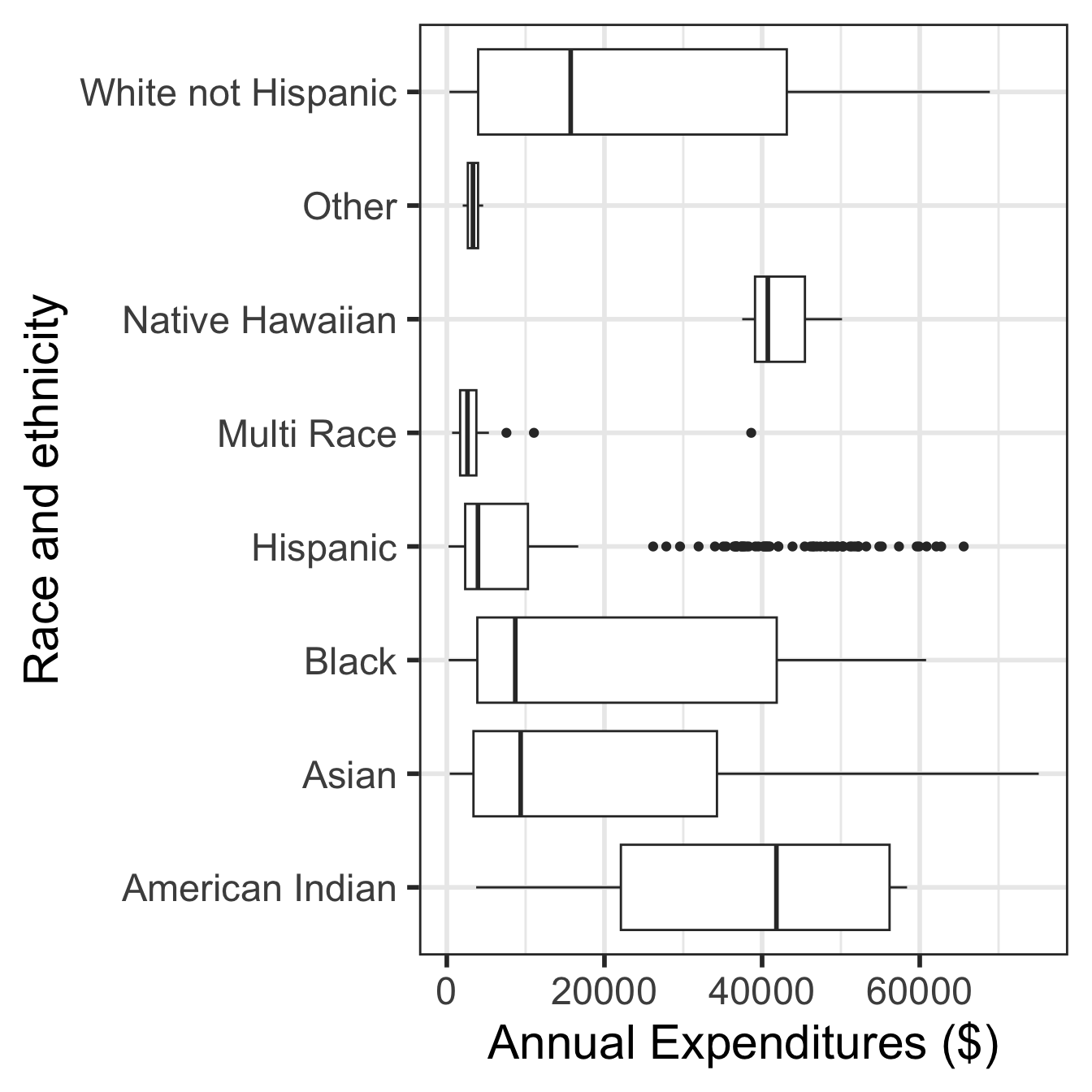
Side-by-side boxplots with data points
Can you determine the following using boxplots?
- distribution shape
- sample size

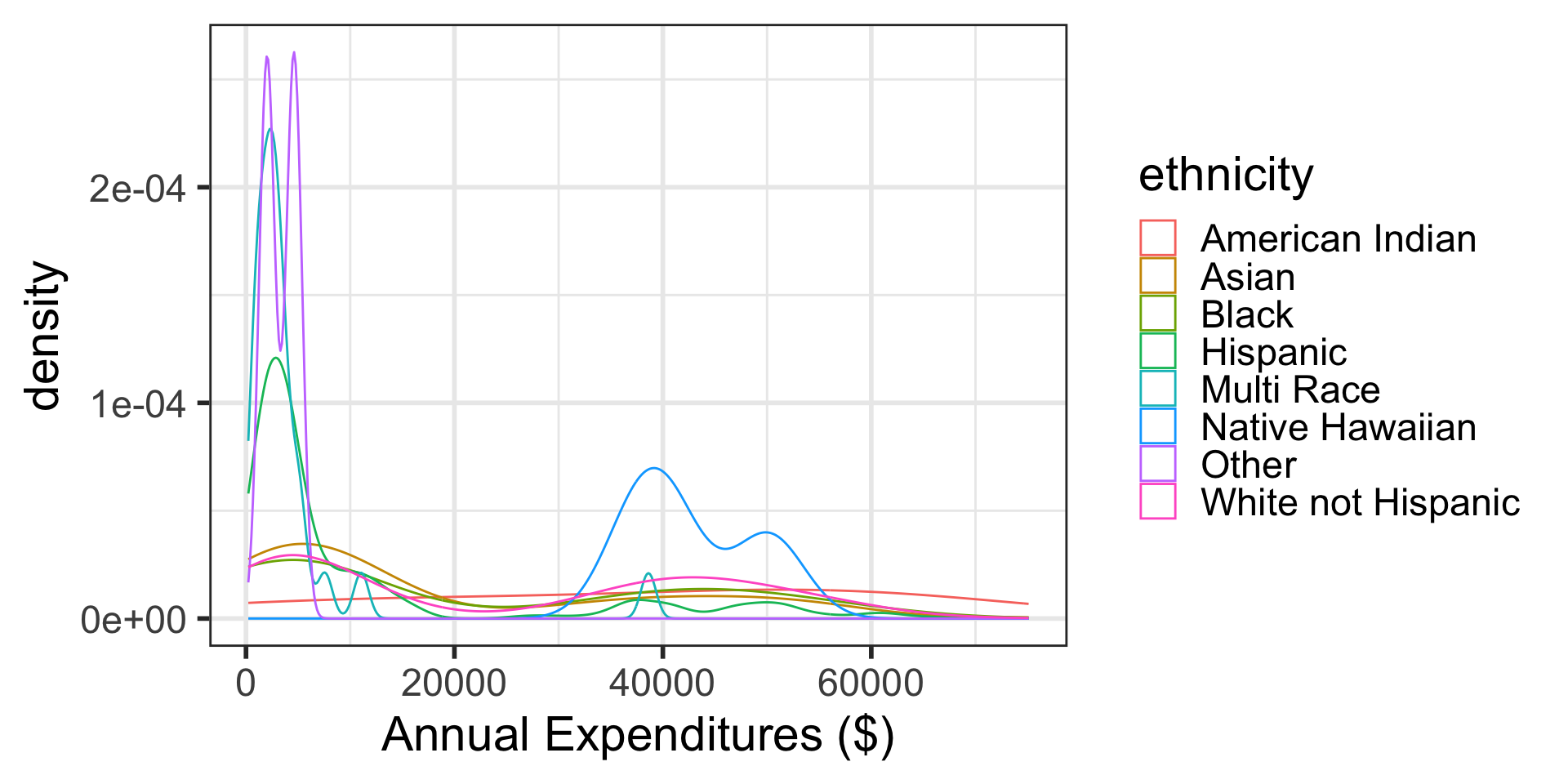
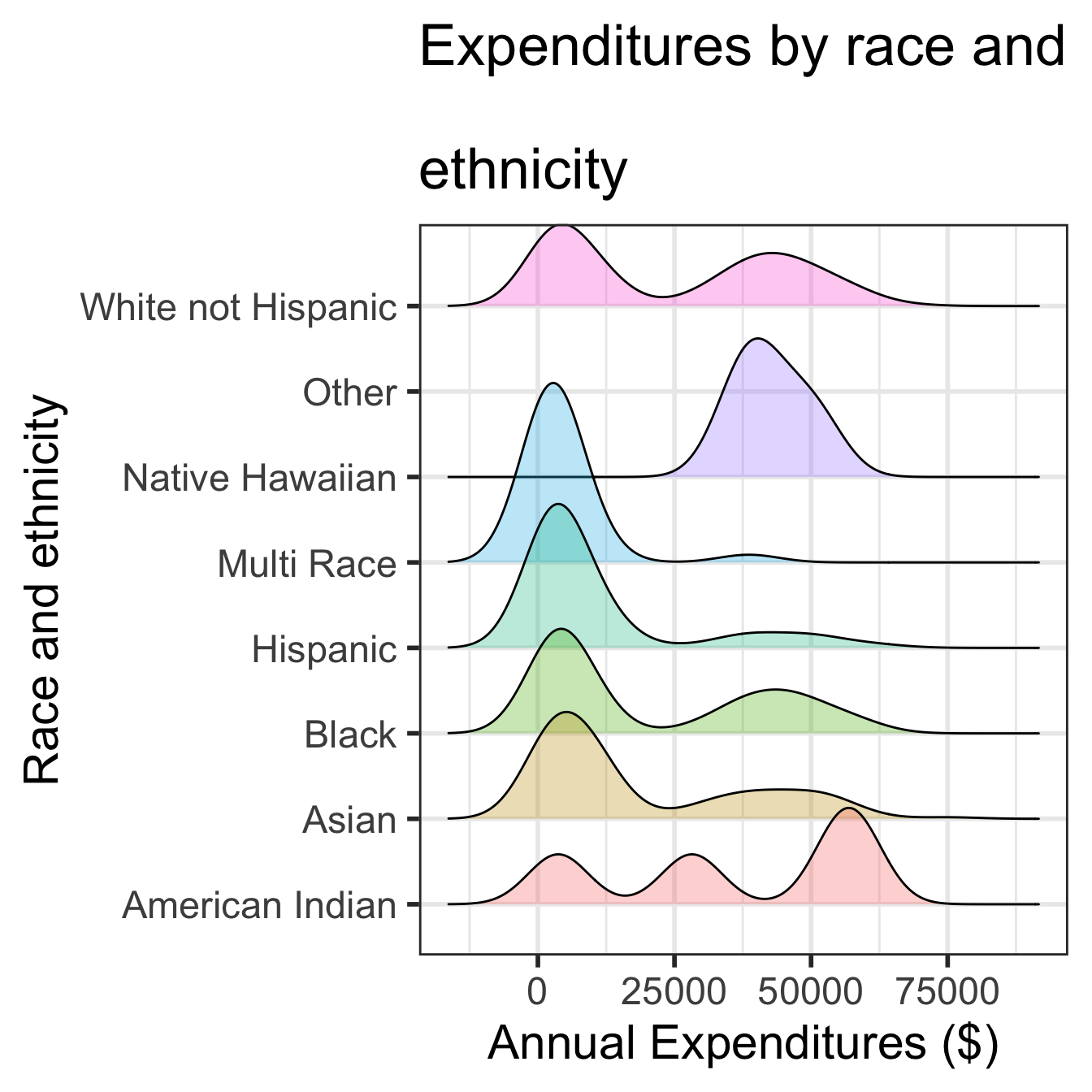
Density plots by group
Ridgeline plot
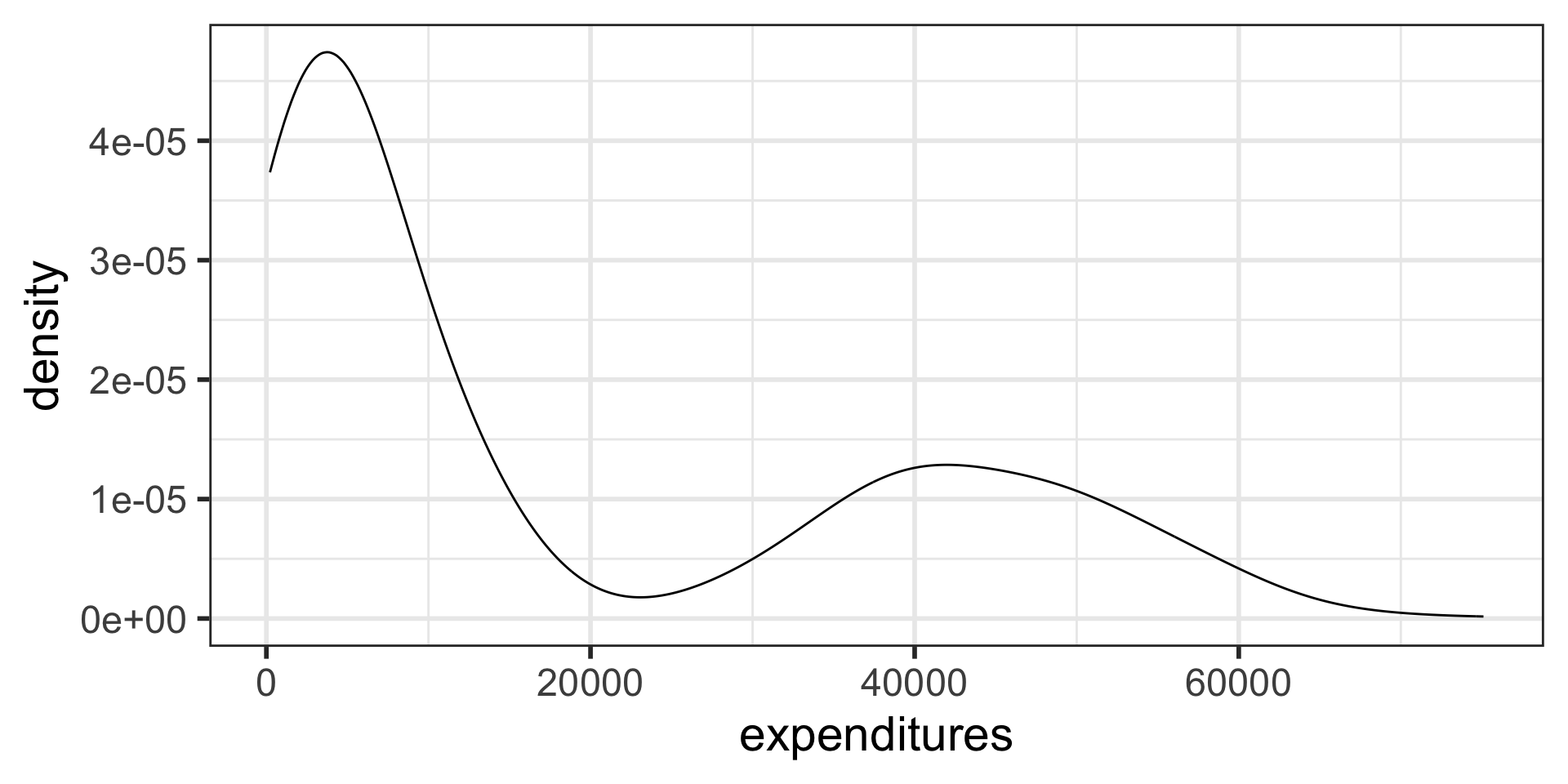
Transforming data (1.4.5)
- We sometimes apply a transformation to highly skewed data to make it more symmetric
- Log transformations are often used for skewed right data
Scatterplots
Response vs. explanatory variables (Section 1.2.3)
- A response variable measures the outcome of interest in a study
- A study will typically examine whether the values of a response variable differ as values of an explanatory variable change

Describe the association between the variables
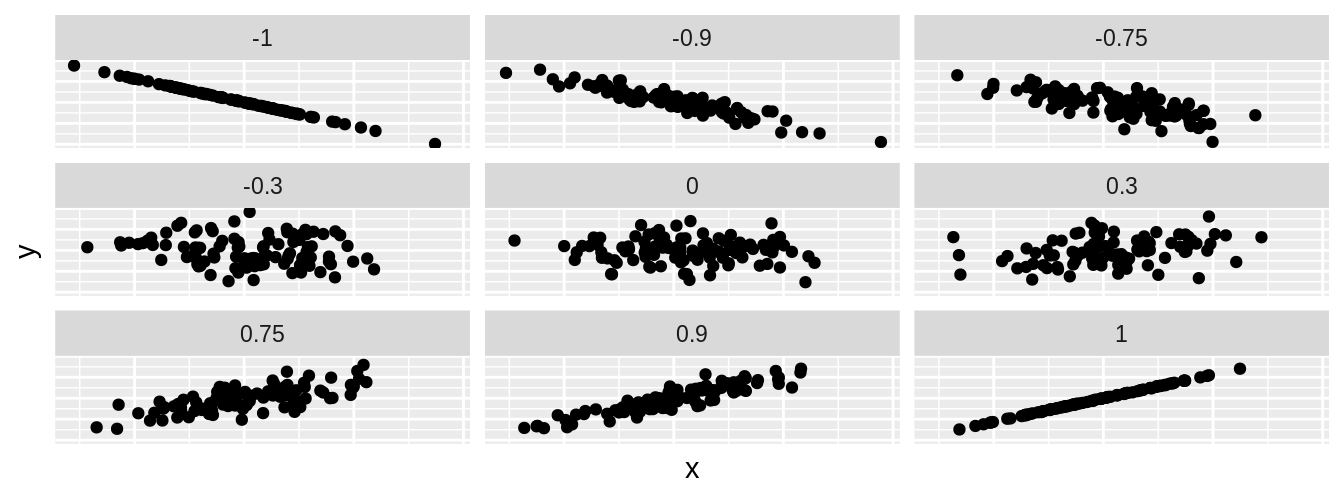
Describing associations between 2 numerical variables
Two variables \(x\) and \(y\) are
positively associated if \(y\) increases as \(x\) increases.
negatively associated if \(y\) decreases as \(x\) increases.
If there is no association between the variables, then we say they are uncorrelated or independent.

- The term “association” is a very general term.
- Can be used for numerical or categorical variables
- Not specifically referring to linear associations
(Pearson) Correlation coefficient \(r\)
\(r = -1\) indicates a perfect negative linear relationship: As one variable increases, the value of the other variable tends to go down, following a straight line.
\(r = 0\) indicates no linear relationship: The values of both variables go up/down independently of each other.
\(r = 1\) indicates a perfect positive linear relationship: As the value of one variable goes up, the value of the other variable tends to go up as well in a linear fashion.
The closer \(r\) is to ±1, the stronger the linear association.
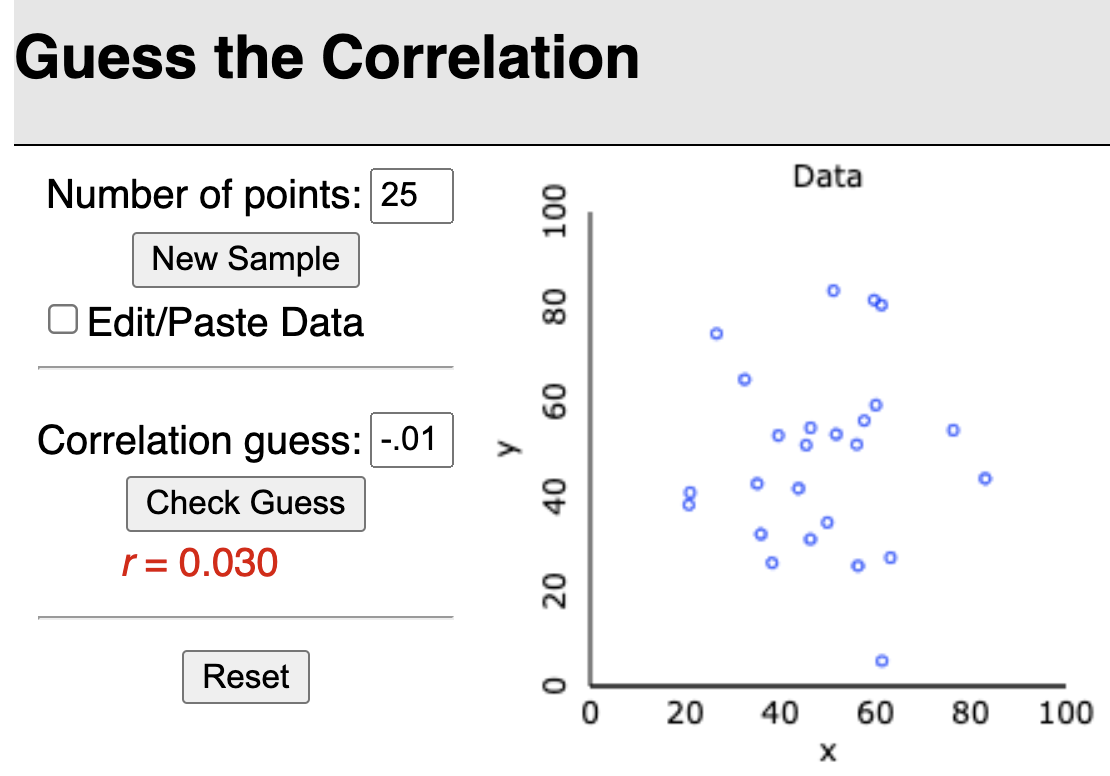
Guess the correlation game!
Rossman & Chance’s applet
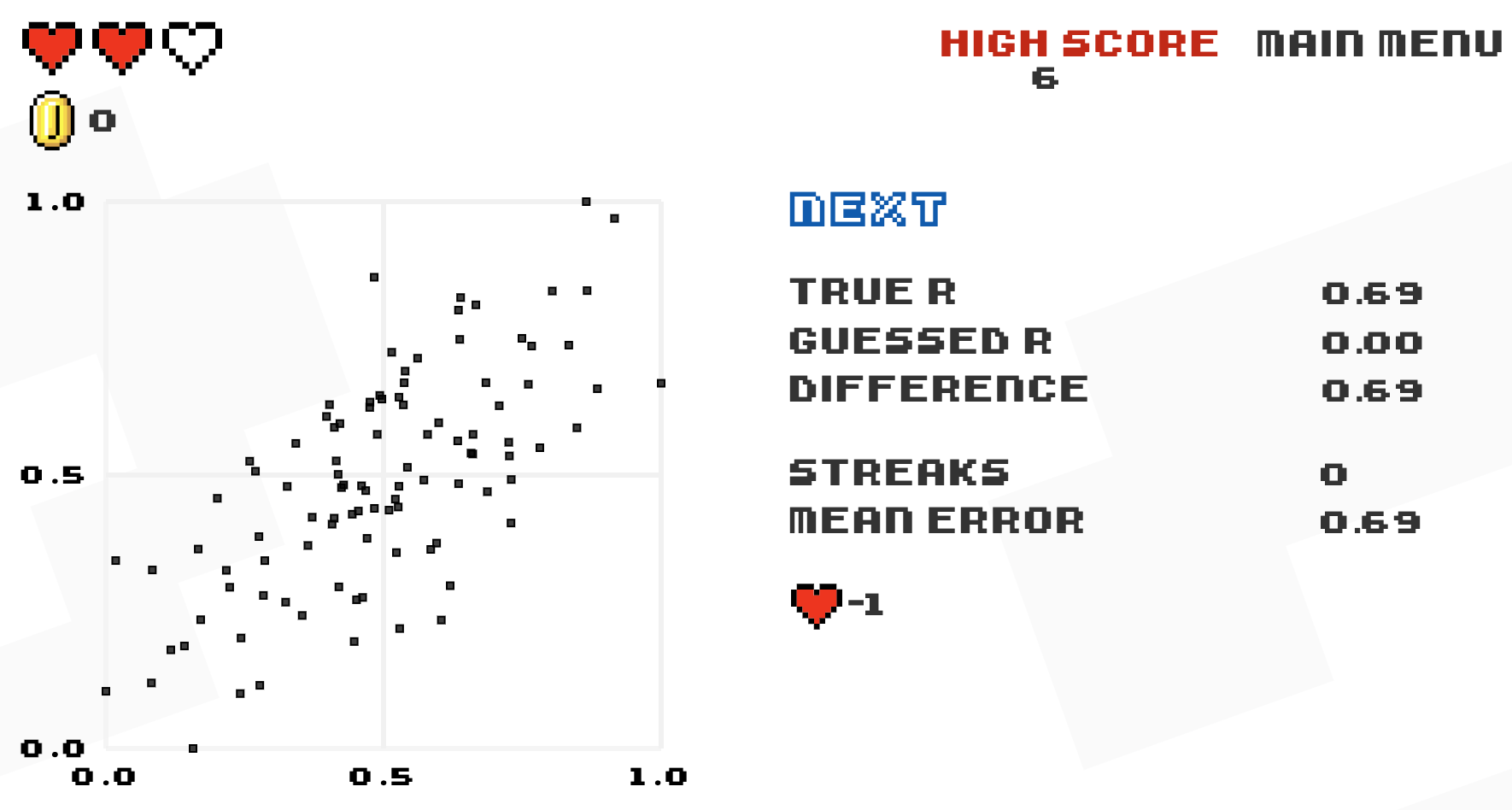
Tracks performance of guess vs. actual, error vs. actual, and error vs. trial
Or, for the Atari-like experience
Scatterplots with color-coded dots
Describe the association between the variables
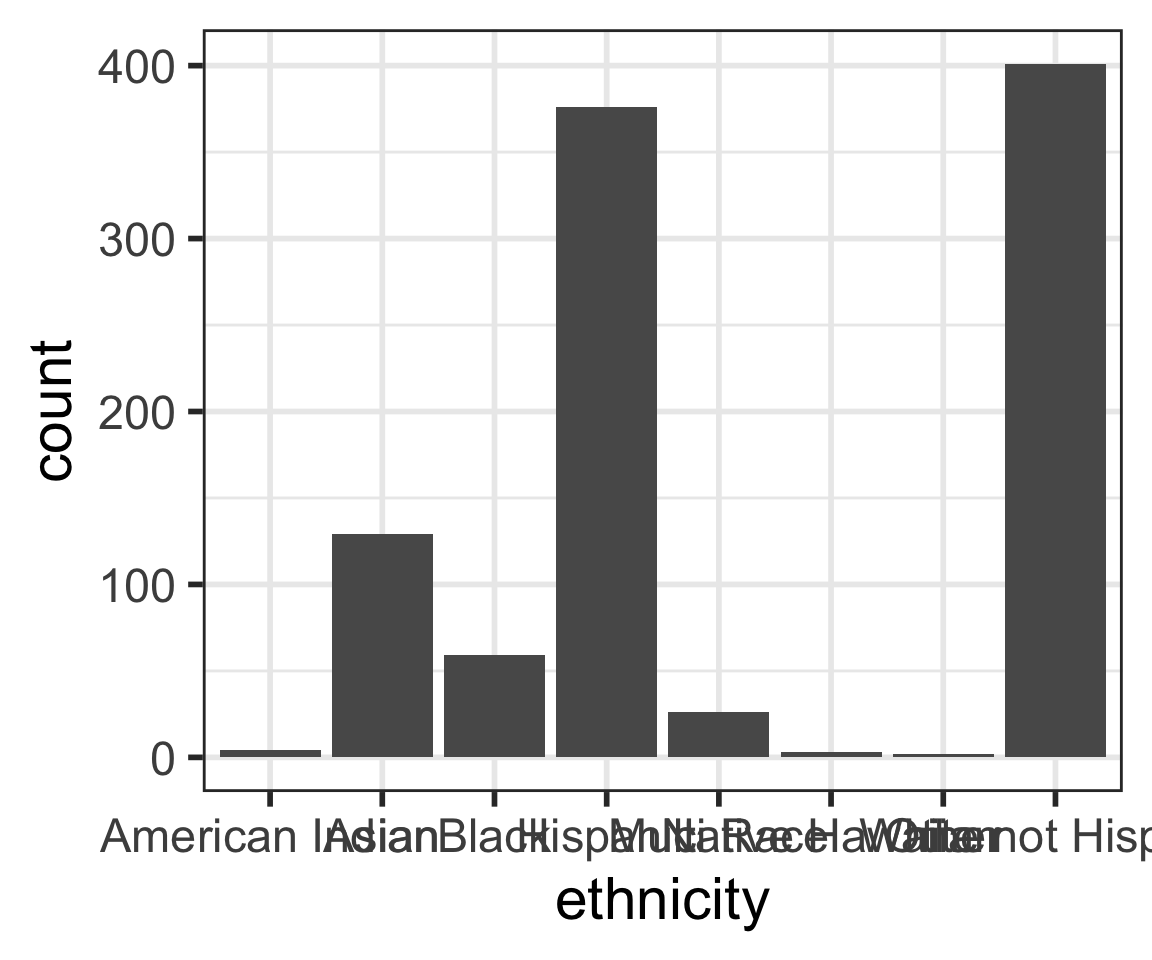
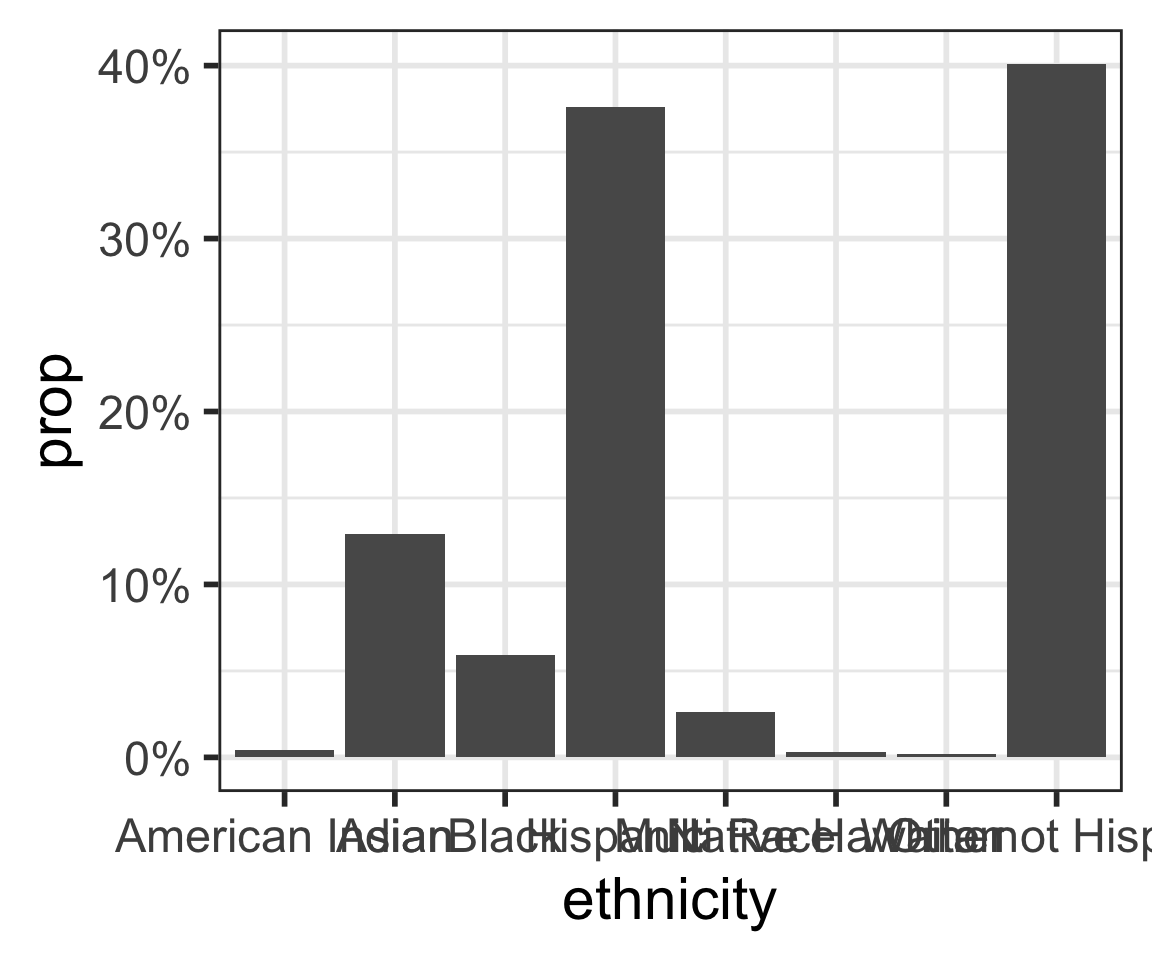
Barplots
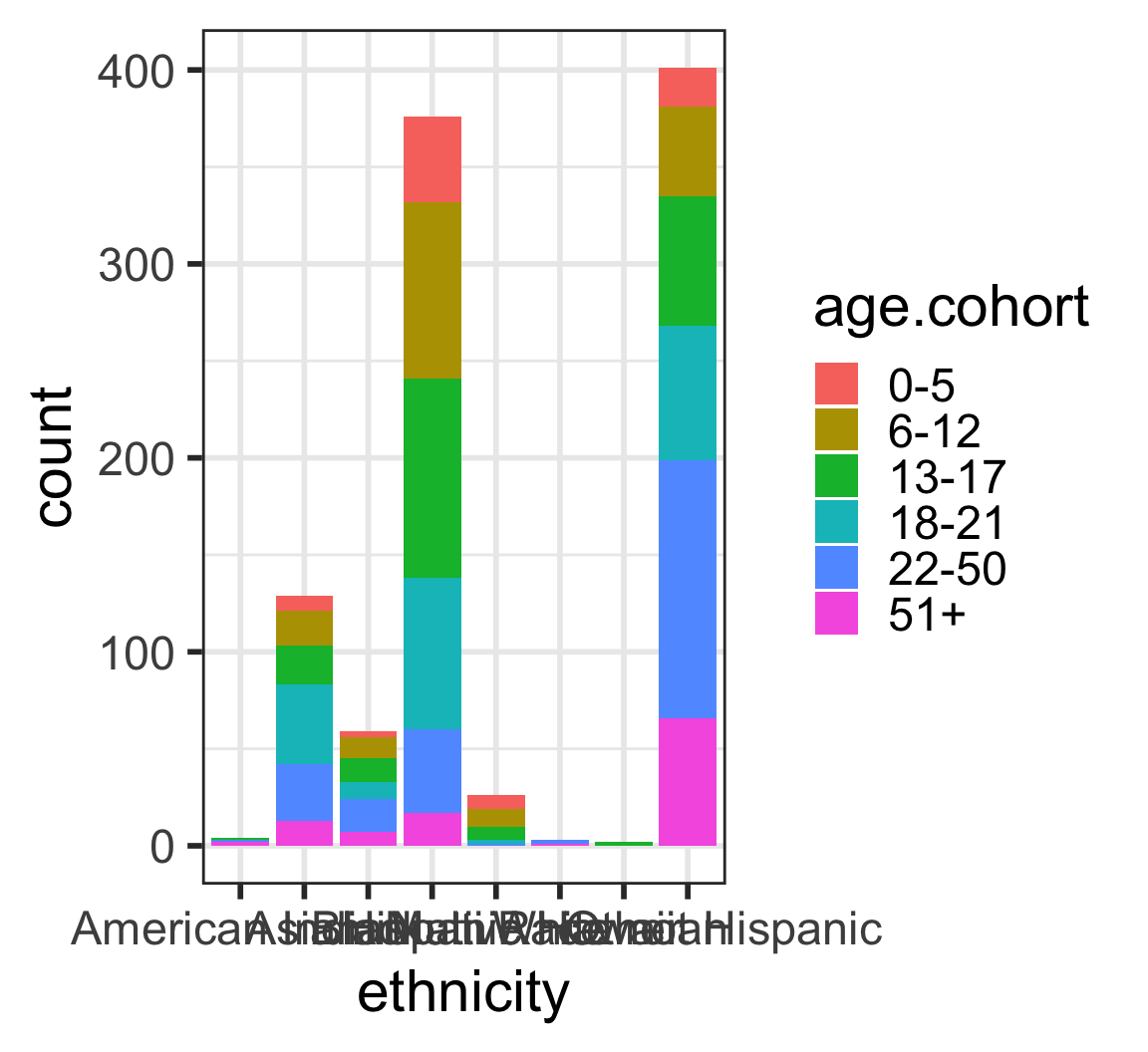
Barplots with 2 variables: segmented bar plots
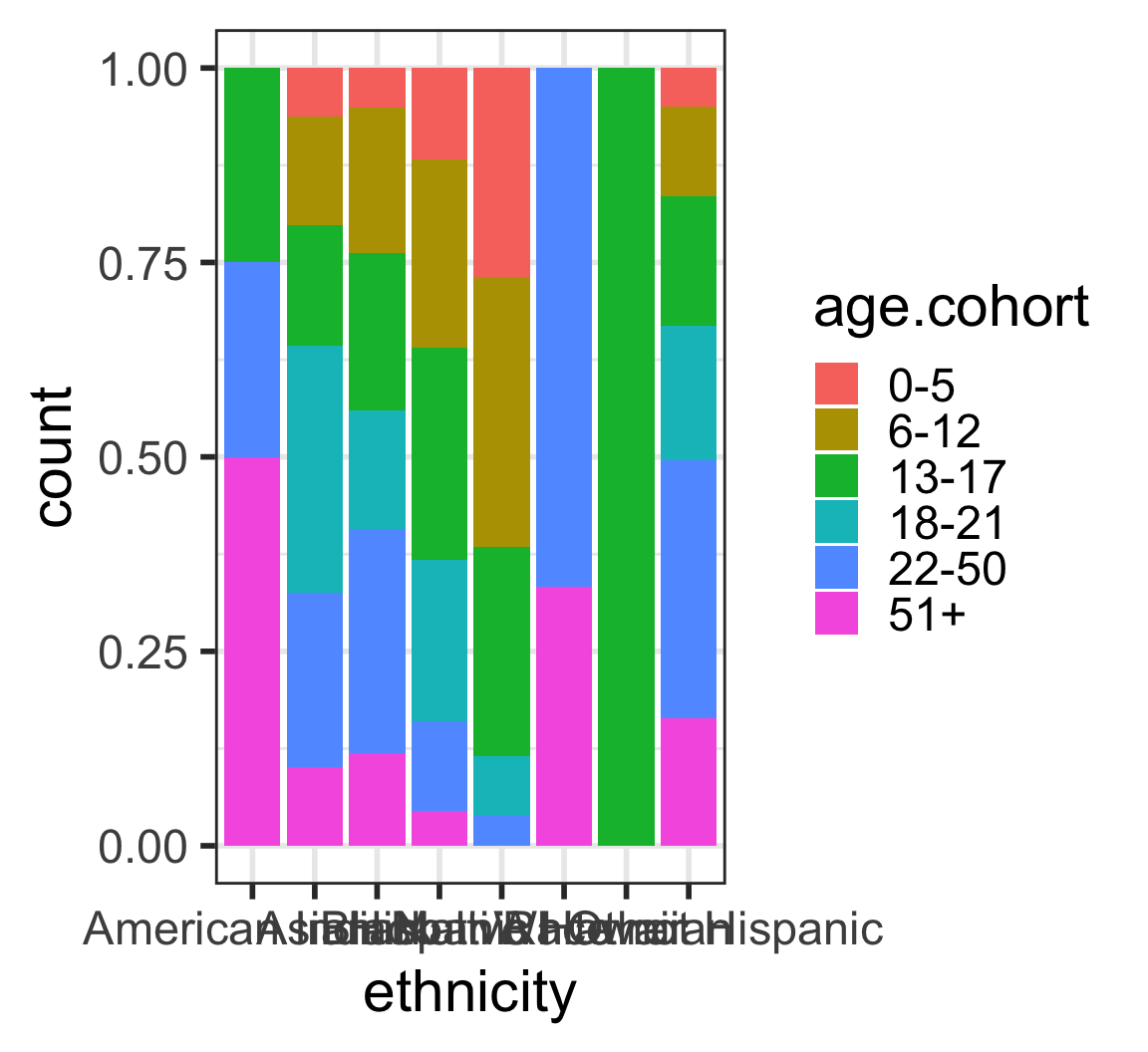
Barplots with 2 variables: side-by-side bar plots